49 stable releases (6 major)
| new 6.4.2 | Apr 1, 2025 |
|---|---|
| 6.4.1 | Mar 31, 2025 |
| 6.0.1 | Feb 6, 2025 |
| 5.0.0 | Jan 22, 2025 |
| 0.1.2 | Jun 14, 2022 |
#86 in HTTP server
592 downloads per month
74KB
1K
SLoC
Reflux
Reflux is a cutting-edge Rust framework designed to streamline the development of microservices with a focus on scalability, flexibility, and usability. By leveraging Rust's performance and safety features, Reflux empowers developers to build robust, high-performance microservices that can seamlessly adapt to evolving business needs. Whether you're scaling up to handle millions of requests or integrating diverse service components, Reflux provides the tools and framework you need to achieve efficient and maintainable microservice architectures. Dive into Reflux and transform the way you build and manage microservices with ease and confidence.
Benefits of using Reflux
- Single Responsibility - Write code that does one thing and does it well. Write simpler and more efficient code.
- Isolation - The code you write is agnostic to the wider Reflux nextwork. Write extendible and flexible programs.
- Scalability - Seamlessly scale your application to meet your requirements. Write adaptable code that scales on-demand.
- Safety - Take full advantages of Rust's memory safety guarantees, ensuring you write and deploy reliable code.
Use cases
- Pipeline workflows - Reflux is perfect for use cases such as ETL (Extract, Transform and Load) applications, image processing and real-time analytics.
- Routing - Leverage the flexibility of Reflux to build routing applications, such as reverse proxies, with safety and simplicity.
- Load balancing - Data can be distributed amongst multiple endpoints, allowing for scaling of applications.
When not to use Reflux
- I/O bound applications. Reflux is designed for CPU-bound applications, where many tasks are run simultaneously. If your use case is I/O focused, it is recommended to use a runtime such as Tokio. However, you can use the two simultaneously - leverage the CPU-bound tasks to Reflux and the IO-bound tasks to Tokio!
- Web servers. Reflux is best served for applications where the data flows in one direction (i.e extraction, transformation, and loading). Whilst it is possible to build a web server with Reflux, the implementaion will be clunky.
Reflux Objects
In Reflux, there are various object types that are available.
Extractor
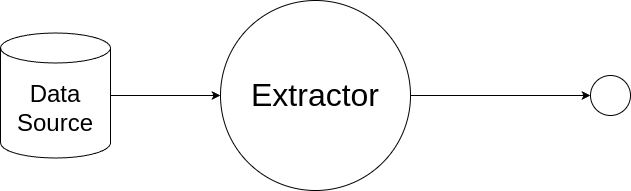
The Extractor is responsible for reading data from an external source (such as a file or socket connection) and yielding data extracted from the source.
When using coroutines in the Extractor, there are two valid methods of yielding data:
- In an infitite loop:
#[coroutine] || {
loop {
yield 1
}
}
This method is useful if you are reading from a constant stream of data, such a socket.
- As a once-off statement:
#[coroutine] || {
yield 1
}
This method is useful if you are reading from a data source one time, such as reading data from a file.
Transformer
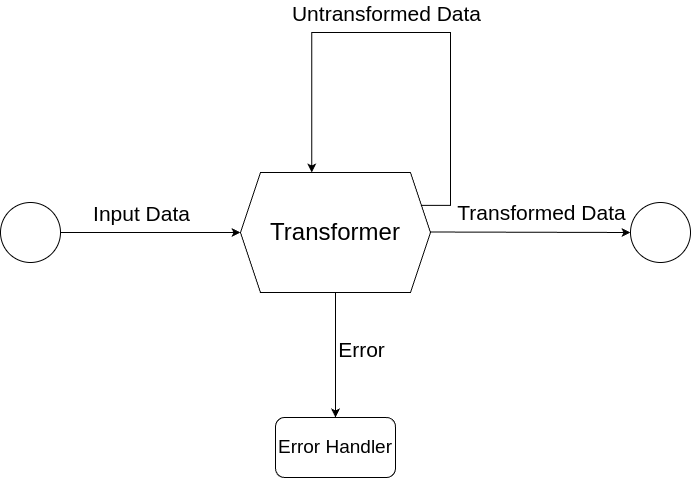
The Transformer is responsible for mutating data. A transformer can convert data from one type to another, or mutate data, but keep the type.
The transformer has three behaviours, represented by the following enum:
enum TransformerResult<O, T, E> {
Transformed(T),
NeedsMoreWork(O),
Error(E),
}
Transformed: TheTransformerhas completed work on the data. This will pass the data along a Reflux pipeline.NeedsMoreWork- TheTransformerneeds to do more work on the data. Data are fed back into theTransformerfor further processing. This behaviour is useful for recursive functions, such as walking through a directory tree.Error- TheTransformerencountered an error whilst processing the data.
Note: As of version 1.2.0, the Transformer error handler simply prints the error to stderr.
Guideline
There may be instances when you may want to yield data as you are iterating through an iterable. If you are yielding in the for loop, the borrow checker will prevent compilation.
For example, the following code snippet will not compile:
#[coroutine] || {
let vals = vec![1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
for i in vals.iter() {
if *i == 6 {
yield *i;
}
}
}
However, you can still achieve this behaviour and satisfy the borrow checker using the following technique:
#[coroutine] || {
let vals = vec![1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
let mut res = None;
for i in vals {
if *i == 6 {
res = Some(*i);
break;
}
}
yield res.unwrap()
}
Balancer
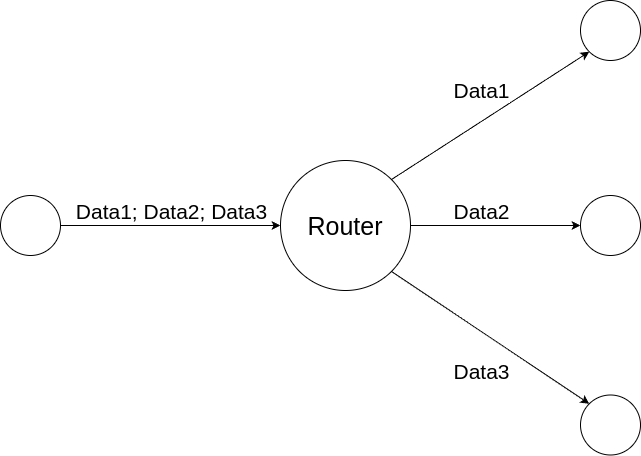
The Balancer is responsible for routing data amongst a set of Receiver s in a Round Robin fasion.
Filter
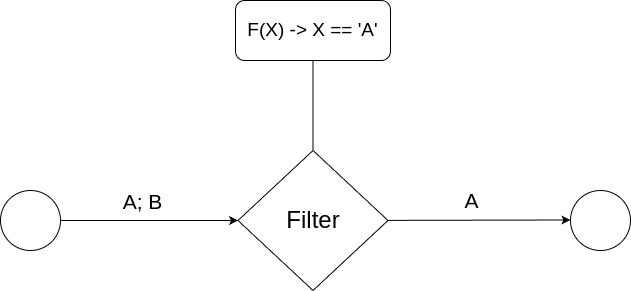
The Filter is responsible for conditionally allowing data to flow through a Reflux pipeline. A predicate is supplied to a Filter and if data satisfies the predicate, it may pass through.
Guideline
Use a pure function as a predicate with a complexity of O(1), if at all possible. Functions with a higher complexity, or that read data from a file or socket have the potential to prevent the predicate from completing execution, either through an error or an infitite loop.
However, for use cases such as spam filters, it may be impossible to avoid using predicates that read from data sources, or with non-constant time complexities.
Broadcast
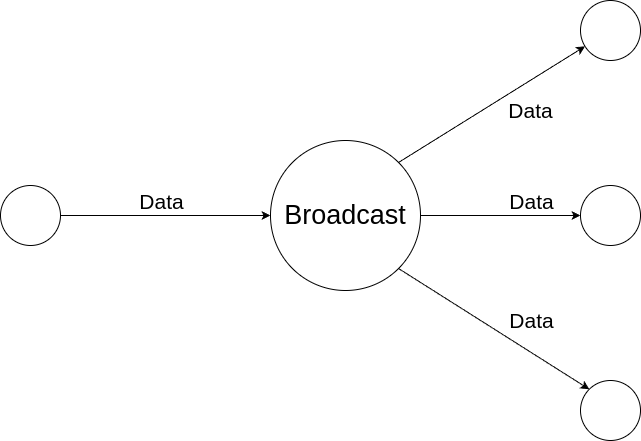
The Broadcast is responsible for broadcasting data to multiple Senders.
Funnel
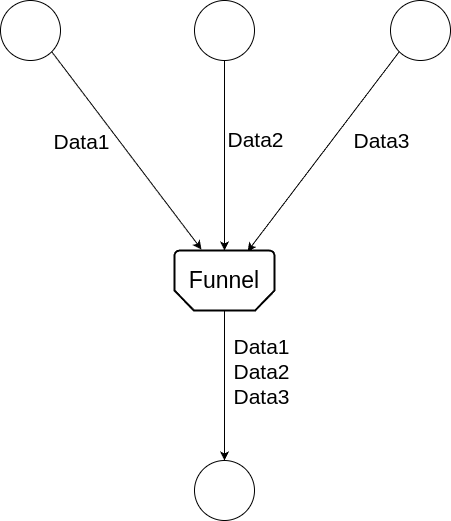
The Funnel is responsible for collecting data from multiple Receiver s and sending the data through to a single Sender.
Caution
The Funnel can potentially be a bottleneck in a Reflux pipeline, causing uncontrolled memory usage. It is advised to connect a small number of Receivers to a Funnel.
Messenger
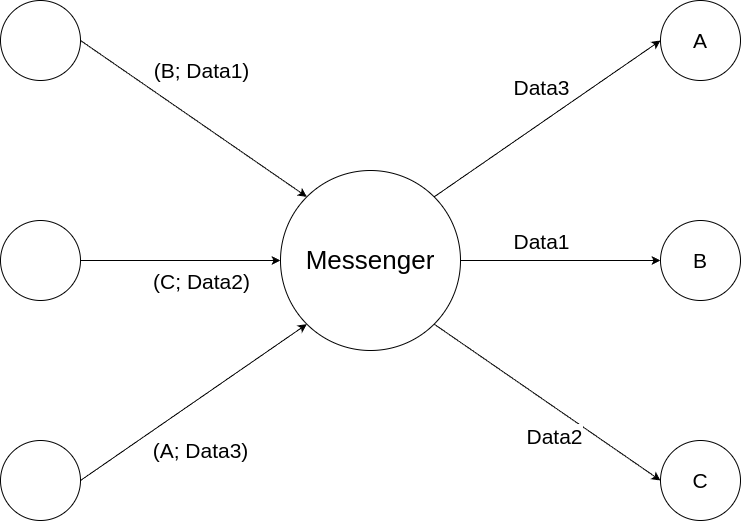
The Messenger is responsible for receiving messages and passing it through to the relevant Sender.
Loader
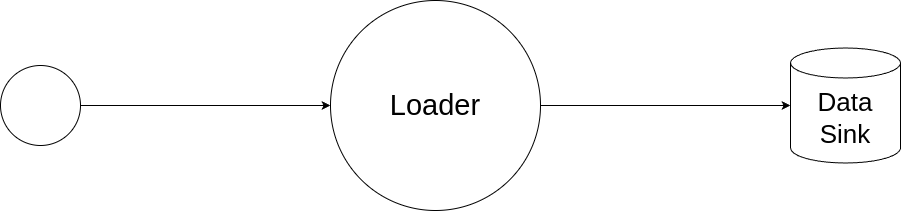
The Loader is the end of a Reflux pipeline. A loader can drop data, or write it to an external source (such as a file or socket).
Stability
Due to coroutines being an unstable feature in Rust, and the evolving development of Reflux, the framework is currently unstable and is subject to change in the future.
Clogging and Thrashing
- Clogging - Clogging is a behaviour whereby a node in a Rust pipeline crashes, but the channels between the node and it's connected neighbor is still active. The channels are written to, but never read from, so the channels start consuming memory. This may result in OOMKilled signals from the kernel, as the program has consumed all available memory.
- Thrashing - Thrasing is the behaviour whereby too many nodes are instantiated, resulting in more CPU time context switching, rather than executing code. Note: The threshold of when this behaviour happens is unknown.
Wishlist
- Detecting and handling clogging.
- Minimise boilerplate code.
- Implement a runtime, allowing for running multiple coroutines on a single thread.
Dependencies
~345KB