45 releases
| 0.9.0 | Nov 18, 2024 |
|---|---|
| 0.8.8 | Sep 22, 2024 |
| 0.8.6 | Jun 16, 2024 |
| 0.8.4 | Feb 27, 2024 |
| 0.2.1 | Oct 23, 2021 |
#17 in HTTP server
2,755 downloads per month
175KB
3K
SLoC

![]()
![]()
![]()
Model Serving made Efficient in the Cloud.
Introduction
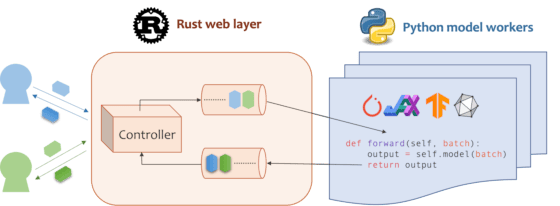
Mosec is a high-performance and flexible model serving framework for building ML model-enabled backend and microservices. It bridges the gap between any machine learning models you just trained and the efficient online service API.
- Highly performant: web layer and task coordination built with Rust 🦀, which offers blazing speed in addition to efficient CPU utilization powered by async I/O
- Ease of use: user interface purely in Python 🐍, by which users can serve their models in an ML framework-agnostic manner using the same code as they do for offline testing
- Dynamic batching: aggregate requests from different users for batched inference and distribute results back
- Pipelined stages: spawn multiple processes for pipelined stages to handle CPU/GPU/IO mixed workloads
- Cloud friendly: designed to run in the cloud, with the model warmup, graceful shutdown, and Prometheus monitoring metrics, easily managed by Kubernetes or any container orchestration systems
- Do one thing well: focus on the online serving part, users can pay attention to the model optimization and business logic
Installation
Mosec requires Python 3.7 or above. Install the latest PyPI package for Linux x86_64 or macOS x86_64/ARM64 with:
pip install -U mosec
# or install with conda
conda install conda-forge::mosec
To build from the source code, install Rust and run the following command:
make package
You will get a mosec wheel file in the dist folder.
Usage
We demonstrate how Mosec can help you easily host a pre-trained stable diffusion model as a service. You need to install diffusers and transformers as prerequisites:
pip install --upgrade diffusers[torch] transformers
Write the server
Click me for server codes with explanations.
Firstly, we import the libraries and set up a basic logger to better observe what happens.
from io import BytesIO
from typing import List
import torch # type: ignore
from diffusers import StableDiffusionPipeline # type: ignore
from mosec import Server, Worker, get_logger
from mosec.mixin import MsgpackMixin
logger = get_logger()
Then, we build an API for clients to query a text prompt and obtain an image based on the stable-diffusion-v1-5 model in just 3 steps.
-
Define your service as a class which inherits
mosec.Worker. Here we also inheritMsgpackMixinto employ the msgpack serialization format(a). -
Inside the
__init__method, initialize your model and put it onto the corresponding device. Optionally you can assignself.examplewith some data to warm up(b) the model. Note that the data should be compatible with your handler's input format, which we detail next. -
Override the
forwardmethod to write your service handler(c), with the signatureforward(self, data: Any | List[Any]) -> Any | List[Any]. Receiving/returning a single item or a tuple depends on whether dynamic batching(d) is configured.
class StableDiffusion(MsgpackMixin, Worker):
def __init__(self):
self.pipe = StableDiffusionPipeline.from_pretrained(
"sd-legacy/stable-diffusion-v1-5", torch_dtype=torch.float16
)
self.pipe.enable_model_cpu_offload()
self.example = ["useless example prompt"] * 4 # warmup (batch_size=4)
def forward(self, data: List[str]) -> List[memoryview]:
logger.debug("generate images for %s", data)
res = self.pipe(data)
logger.debug("NSFW: %s", res[1])
images = []
for img in res[0]:
dummy_file = BytesIO()
img.save(dummy_file, format="JPEG")
images.append(dummy_file.getbuffer())
return images
Note
(a) In this example we return an image in the binary format, which JSON does not support (unless encoded with base64 that makes the payload larger). Hence, msgpack suits our need better. If we do not inherit MsgpackMixin, JSON will be used by default. In other words, the protocol of the service request/response can be either msgpack, JSON, or any other format (check our mixins).
(b) Warm-up usually helps to allocate GPU memory in advance. If the warm-up example is specified, the service will only be ready after the example is forwarded through the handler. However, if no example is given, the first request's latency is expected to be longer. The example should be set as a single item or a tuple depending on what forward expects to receive. Moreover, in the case where you want to warm up with multiple different examples, you may set multi_examples (demo here).
(c) This example shows a single-stage service, where the StableDiffusion worker directly takes in client's prompt request and responds the image. Thus the forward can be considered as a complete service handler. However, we can also design a multi-stage service with workers doing different jobs (e.g., downloading images, model inference, post-processing) in a pipeline. In this case, the whole pipeline is considered as the service handler, with the first worker taking in the request and the last worker sending out the response. The data flow between workers is done by inter-process communication.
(d) Since dynamic batching is enabled in this example, the forward method will wishfully receive a list of string, e.g., ['a cute cat playing with a red ball', 'a man sitting in front of a computer', ...], aggregated from different clients for batch inference, improving the system throughput.
Finally, we append the worker to the server to construct a single-stage workflow (multiple stages can be pipelined to further boost the throughput, see this example), and specify the number of processes we want it to run in parallel (num=1), and the maximum batch size (max_batch_size=4, the maximum number of requests dynamic batching will accumulate before timeout; timeout is defined with the max_wait_time=10 in milliseconds, meaning the longest time Mosec waits until sending the batch to the Worker).
if __name__ == "__main__":
server = Server()
# 1) `num` specifies the number of processes that will be spawned to run in parallel.
# 2) By configuring the `max_batch_size` with the value > 1, the input data in your
# `forward` function will be a list (batch); otherwise, it's a single item.
server.append_worker(StableDiffusion, num=1, max_batch_size=4, max_wait_time=10)
server.run()
Run the server
Click me to see how to run and query the server.
The above snippets are merged in our example file. You may directly run at the project root level. We first have a look at the command line arguments (explanations here):
python examples/stable_diffusion/server.py --help
Then let's start the server with debug logs:
python examples/stable_diffusion/server.py --log-level debug --timeout 30000
Open http://127.0.0.1:8000/openapi/swagger/ in your browser to get the OpenAPI doc.
And in another terminal, test it:
python examples/stable_diffusion/client.py --prompt "a cute cat playing with a red ball" --output cat.jpg --port 8000
You will get an image named "cat.jpg" in the current directory.
You can check the metrics:
curl http://127.0.0.1:8000/metrics
That's it! You have just hosted your stable-diffusion model as a service! 😉
Examples
More ready-to-use examples can be found in the Example section. It includes:
- Pipeline: a simple echo demo even without any ML model.
- Request validation: validate the request with type annotation.
- Multiple route: serve multiple models in one service
- Embedding service: OpenAI compatible embedding service
- Reranking service: rerank a list of passages based on a query
- Shared memory IPC: inter-process communication with shared memory.
- Customized GPU allocation: deploy multiple replicas, each using different GPUs.
- Customized metrics: record your own metrics for monitoring.
- Jax jitted inference: just-in-time compilation speeds up the inference.
- Compression: enable request/response compression.
- PyTorch deep learning models:
- sentiment analysis: infer the sentiment of a sentence.
- image recognition: categorize a given image.
- stable diffusion: generate images based on texts, with msgpack serialization.
Configuration
- Dynamic batching
max_batch_sizeandmax_wait_time (millisecond)are configured when you callappend_worker.- Make sure inference with the
max_batch_sizevalue won't cause the out-of-memory in GPU. - Normally,
max_wait_timeshould be less than the batch inference time. - If enabled, it will collect a batch either when the number of accumulated requests reaches
max_batch_sizeor whenmax_wait_timehas elapsed. The service will benefit from this feature when the traffic is high.
- Check the arguments doc for other configurations.
Deployment
- If you're looking for a GPU base image with
mosecinstalled, you can check the official imagemosecorg/mosec. For the complex use case, check out envd. - This service doesn't need Gunicorn or NGINX, but you can certainly use the ingress controller when necessary.
- This service should be the PID 1 process in the container since it controls multiple processes. If you need to run multiple processes in one container, you will need a supervisor. You may choose Supervisor or Horust.
- Remember to collect the metrics.
mosec_service_batch_size_bucketshows the batch size distribution.mosec_service_batch_duration_second_bucketshows the duration of dynamic batching for each connection in each stage (starts from receiving the first task).mosec_service_process_duration_second_bucketshows the duration of processing for each connection in each stage (including the IPC time but excluding themosec_service_batch_duration_second_bucket).mosec_service_remaining_taskshows the number of currently processing tasks.mosec_service_throughputshows the service throughput.
- Stop the service with
SIGINT(CTRL+C) orSIGTERM(kill {PID}) since it has the graceful shutdown logic.
Performance tuning
- Find out the best
max_batch_sizeandmax_wait_timefor your inference service. The metrics will show the histograms of the real batch size and batch duration. Those are the key information to adjust these two parameters. - Try to split the whole inference process into separate CPU and GPU stages (ref DistilBERT). Different stages will be run in a data pipeline, which will keep the GPU busy.
- You can also adjust the number of workers in each stage. For example, if your pipeline consists of a CPU stage for preprocessing and a GPU stage for model inference, increasing the number of CPU-stage workers can help to produce more data to be batched for model inference at the GPU stage; increasing the GPU-stage workers can fully utilize the GPU memory and computation power. Both ways may contribute to higher GPU utilization, which consequently results in higher service throughput.
- For multi-stage services, note that the data passing through different stages will be serialized/deserialized by the
serialize_ipc/deserialize_ipcmethods, so extremely large data might make the whole pipeline slow. The serialized data is passed to the next stage through rust by default, you could enable shared memory to potentially reduce the latency (ref RedisShmIPCMixin). - You should choose appropriate
serialize/deserializemethods, which are used to decode the user request and encode the response. By default, both are using JSON. However, images and embeddings are not well supported by JSON. You can choose msgpack which is faster and binary compatible (ref Stable Diffusion). - Configure the threads for OpenBLAS or MKL. It might not be able to choose the most suitable CPUs used by the current Python process. You can configure it for each worker by using the env (ref custom GPU allocation).
- Enable HTTP/2 from client side.
mosecautomatically adapts to user's protocol (e.g., HTTP/2) since v0.8.8.
Adopters
Here are some of the companies and individual users that are using Mosec:
- Modelz: Serverless platform for ML inference.
- MOSS: An open sourced conversational language model like ChatGPT.
- TencentCloud: Tencent Cloud Machine Learning Platform, using Mosec as the core inference server framework.
- TensorChord: Cloud native AI infrastructure company.
- OAT: Serving reward models for online LLM alignment.
Citation
If you find this software useful for your research, please consider citing
@software{yang2021mosec,
title = {{MOSEC: Model Serving made Efficient in the Cloud}},
author = {Yang, Keming and Liu, Zichen and Cheng, Philip},
url = {https://github.com/mosecorg/mosec},
year = {2021}
}
Contributing
We welcome any kind of contribution. Please give us feedback by raising issues or discussing on Discord. You could also directly contribute your code and pull request!
To start develop, you can use envd to create an isolated and clean Python & Rust environment. Check the envd-docs or build.envd for more information.
Dependencies
~18–29MB
~428K SLoC