1 stable release
| 1.0.0 | Feb 25, 2024 |
|---|
#13 in #ripgrep
33KB
653 lines
Just the code
A ripgrep preprocessor, that strips away comments and strings from your code, allowing you to search for just the code, sometimes greatly reducing noise in your search results:
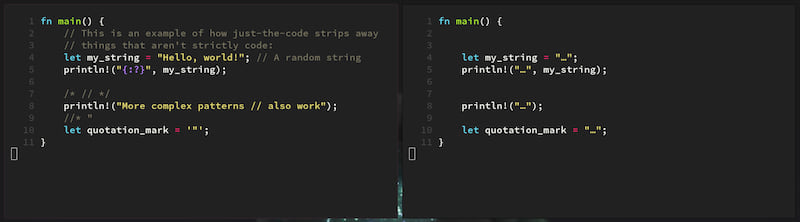 Left: original file. Right: output of
Left: original file. Right: output of just-the-code.
Its main advantages over other methods are:
- It is efficient, since it does not need to build a syntax tree or compile your code
- It runs in your terminal and can thus be integrated with other CLI tools
- It can easily be customized to fit your needs: you only need to specify how comments and strings look like for it to work with your language of choice
- Accurately handles nested comments, strings and interactions between different kinds of comments
- Integrates natively with
ripgrep, so using it is as simple as passing one additional parameter
Installation
If you have cargo installed already, then you simply need to run:
cargo install just-the-code
If you instead wish to make changes to the source code, or install it somewhere else, then you can run the following:
# Grab the code
git clone https://github.com/adri326/just-the-code/
# Navigate to the correct repository
cd just-the-code/
# Build the code
cargo build --release
# The built binary will be ./target/release/just-the-code
Usage
To use this tool with ripgrep, simply add --pre just-the-code to your command. For instance:
# Noisy, since a lot of "hello"s are present in strings in the code:
rg "hello"
# No more noise :)
rg --pre just-the-code "hello"
Alternatively, you can use the tool in standalone mode. For instance:
just-the-code src/parse.rs | bat --language rust
A few options are available to customize just-the-code's behavior, which can be seen by running just-the-code --help.
To make these options work together with ripgrep, you will need to create custom bash scripts that themselves invoke just-the-code with the options you need.
You can find more information on the ripgrep guide.
Configuring
To configure just-the-code, you will need to create the file ~/.config/just-the-code/config.toml.
There are a few global options available in it, but most will be language-specific:
# Whether or not to keep strings in the output
keep_strings = false
[lang.rust]
# Single-line comment tokens
line_comments = ["//"]
# Multi-line comment tokens, grouped as pairs
multiline_comments = [["/*", "*/"]]
# String delimiters
strings = ["\"", "'"]
# Tokens to ignore
blacklist = ["\\\"", "\\\\"]
# Whether or not to allow nested comments
nested_comments = false
The main logic of just-the-code has been made generic enough that you only need to tell it how strings and comments
look like for it to work with your language of choice. To do so, you will need to specify the following:
- Single-line comment tokens (
line_comments): for instance//or#; anything after them will be considered part of a comment, and multiline comments cannot be opened after them. - Multi-line comment delimiters (
multiline_comments): for instance/*and*/; single-line comments between them will be ignored. They are grouped as opening/closing pairs. - String delimiters (
strings): commenting tokens in strings will be ignored, and string delimiters will be ignored in comments. - Blacklist tokens (
blacklist): any of the tokens specified will not be matched if it overlaps with a blacklisted token. This lets you blacklist\"in strings, for instance. - Whether or not to allow nested comments (
nested_comments): if enabled, thena /* /* */ */ bwill becomea b. If disabled (which is the default), that same piece of code will instead becomea */ b.
Note on \"
If your languages uses " for strings and allows one to escape quotation marks within strings by typing \",
then simply adding \" to the blacklist is not going to be enough:
"\\" will parse incorrectly, since \" will be seen as an escaped quotation mark.
To fix that, blacklist tokens are implemented to be mutually exclusive:
two blacklist tokens cannot overlap.
This means that if you also add \\ to the blacklist, then "\\" will now parse correctly:
\\ will be seen as one blacklist token, blocking \" from being interpreted as an escaped quotation mark.
Known issues
The performance of ripgrep severely drops when adding --pre, since ripgrep essentially needs to fork() once for each file searched.
It might be possible in the future to integrate just-the-code directly within ripgrep, so that everything can be done within the same process.
Dependencies
~2–13MB
~106K SLoC