41 releases (5 breaking)
| 0.6.7 | Nov 9, 2024 |
|---|---|
| 0.5.6 | Oct 10, 2024 |
| 0.4.0 | Oct 4, 2024 |
| 0.3.0 | Sep 1, 2024 |
| 0.1.0 | Jul 21, 2024 |
#37 in Command line utilities
85 downloads per month
45KB
891 lines
grip-grab (gg) 🧤
A fast, more lightweight ripgrep alternative for daily use cases.
❯ gg "\b(Read|Write)Half[^<]" tokio/src
https://github.com/user-attachments/assets/13406bea-b6f2-4629-b814-366713a8d90d
Installation
Using Cargo
cargo install grip-grab
NOTE: if using zsh with the git plugin, you might need to unalias gg in order for grip-grab's gg to work:
echo 'unalias gg' >> ~/.zshrc
source ~/.zshrc
Benchmarks
The general idea
With default settings for both tools, gg will typically be faster than rg on small to moderatly sized codebases (<= a couple milion lines) running on everyday machines because of its default thread heuristic. rg will typically be faster out of the box on larger corpora (think a checkout of the linux kernel) and machines with more logical cpus. Note that you still can tweak gg with the -T argument to achieve similar performance in those cases.
The following discussion with ripgrep's author on HackerNews might also provide more insights regarding this tool's performance (including more benchmarks across different machines and corpora).
NOTE: The following benchmarks were run on an M3 Macbook Pro with 16GB of RAM and 8 logical CPUs.
The curl codebase (approx. half a milion lines)
hyperfine -m 200 "gg '[A-Z]+_NOBODY' ." "rg '[A-Z]+_NOBODY' ." "ggrep -rE '[A-Z]+_NOBODY' ."
Benchmark 1: gg '[A-Z]+_NOBODY' .
Time (mean ± σ): 18.5 ms ± 0.7 ms [User: 10.5 ms, System: 47.9 ms]
Range (min … max): 17.0 ms … 19.9 ms 200 runs
Benchmark 2: rg '[A-Z]+_NOBODY' .
Time (mean ± σ): 37.0 ms ± 4.6 ms [User: 15.1 ms, System: 201.0 ms]
Range (min … max): 23.3 ms … 60.5 ms 200 runs
Benchmark 3: ggrep -rE '[A-Z]+_NOBODY' .
Time (mean ± σ): 68.5 ms ± 0.6 ms [User: 27.2 ms, System: 40.4 ms]
Range (min … max): 64.6 ms … 70.4 ms 200 runs
Summary
gg '[A-Z]+_NOBODY' . ran
2.00 ± 0.26 times faster than rg '[A-Z]+_NOBODY' .
3.71 ± 0.14 times faster than ggrep -rE '[A-Z]+_NOBODY' .
Plaintext searches
hyperfine -m 100 "gg 'test'" "rg 'test'" "ggrep -rE 'test'"
Benchmark 1: gg 'test'
Time (mean ± σ): 22.3 ms ± 1.1 ms [User: 16.5 ms, System: 51.0 ms]
Range (min … max): 20.4 ms … 27.7 ms 100 runs
Benchmark 2: rg 'test'
Time (mean ± σ): 49.7 ms ± 2.7 ms [User: 23.4 ms, System: 298.3 ms]
Range (min … max): 42.0 ms … 55.5 ms 100 runs
Benchmark 3: ggrep -rE 'test'
Time (mean ± σ): 52.3 ms ± 0.9 ms [User: 14.6 ms, System: 37.0 ms]
Range (min … max): 50.1 ms … 56.9 ms 100 runs
Summary
gg 'test' ran
2.23 ± 0.16 times faster than rg 'test'
2.34 ± 0.12 times faster than ggrep -rE 'test'
The tokio codebase (approx. 160k lines)
https://github.com/tokio-rs/tokio
hyperfine -m 200 "gg 'in<\w, W>'" "rg 'in<\w, W>'" "ggrep -r 'in<[[:alnum:]], W>'"
Benchmark 1: gg 'in<\w, W>'
Time (mean ± σ): 7.4 ms ± 0.7 ms [User: 4.5 ms, System: 6.8 ms]
Range (min … max): 6.0 ms … 10.3 ms 208 runs
Benchmark 2: rg 'in<\w, W>'
Time (mean ± σ): 8.8 ms ± 0.8 ms [User: 5.9 ms, System: 16.5 ms]
Range (min … max): 6.7 ms … 10.7 ms 200 runs
Benchmark 3: ggrep -r 'in<[[:alnum:]], W>'
Time (mean ± σ): 118.3 ms ± 2.1 ms [User: 100.8 ms, System: 16.5 ms]
Range (min … max): 114.3 ms … 127.4 ms 200 runs
Summary
gg 'in<\w, W>' ran
1.19 ± 0.15 times faster than rg 'in<\w, W>'
15.92 ± 1.54 times faster than ggrep -r 'in<[[:alnum:]], W>'
Plaintext searches These typically take <5ms on the tokio repository which is too low to benchmark with a tool like hyperfine.
The neovim codebase (approx. 1.3 milion lines)
https://github.com/neovim/neovim
hyperfine --warmup 100 "gg '[a-z]+_buf\b'" "rg '[a-z]+_buf\b'" "ggrep -rE '[a-z]+_buf\b'"
Benchmark 1: gg '[a-z]+_buf\b'
Time (mean ± σ): 19.0 ms ± 1.2 ms [User: 12.4 ms, System: 54.4 ms]
Range (min … max): 16.8 ms … 22.6 ms 113 runs
Benchmark 2: rg '[a-z]+_buf\b'
Time (mean ± σ): 36.0 ms ± 4.9 ms [User: 14.8 ms, System: 200.5 ms]
Range (min … max): 23.9 ms … 46.2 ms 75 runs
Benchmark 3: ggrep -rE '[a-z]+_buf\b'
Time (mean ± σ): 75.7 ms ± 0.9 ms [User: 36.3 ms, System: 39.4 ms]
Range (min … max): 74.1 ms … 78.1 ms 36 runs
Summary
gg '[a-z]+_buf\b' ran
1.89 ± 0.29 times faster than rg '[a-z]+_buf\b'
3.99 ± 0.26 times faster than ggrep -rE '[a-z]+_buf\b'
Plaintext searches
hyperfine --warmup 100 -m 100 "gg 'test'" "rg 'test'" "ggrep -rE 'test'"
Benchmark 1: gg 'test'
Time (mean ± σ): 21.0 ms ± 0.8 ms [User: 15.3 ms, System: 48.1 ms]
Range (min … max): 18.9 ms … 23.2 ms 114 runs
Benchmark 2: rg 'test'
Time (mean ± σ): 42.4 ms ± 3.6 ms [User: 19.5 ms, System: 253.3 ms]
Range (min … max): 34.9 ms … 63.4 ms 100 runs
Benchmark 3: ggrep -rE 'test'
Time (mean ± σ): 65.3 ms ± 1.6 ms [User: 27.8 ms, System: 36.7 ms]
Range (min … max): 63.2 ms … 78.4 ms 100 runs
Summary
gg 'test' ran
2.02 ± 0.19 times faster than rg 'test'
3.11 ± 0.15 times faster than ggrep -rE 'test'
Usage
❯ gg --help
A faster, more lightweight ripgrep alternative for day to day usecases.
Usage: gg [OPTIONS] [PATTERN] [PATHS]... [COMMAND]
Commands:
upgrade Upgrade the crate to its latest version
help Print this message or the help of the given subcommand(s)
Arguments:
[PATTERN] a regex pattern to search for
[PATHS]... path in which to search recursively
Options:
-e, --patterns <PATTERNS>
you can specify multiple patterns using -e "pattern1" -e "pattern2" etc
-I, --ignore-paths <IGNORE_PATHS>
paths to ignore when recursively walking target directory
-G, --disregard-gitignore
disregard .gitignore rules when recursively walking directory (defaults to false)
-T, --n-threads <N_THREADS>
number of threads to use [default: 4]
-U, --multiline
enable multiline matching
--json
output in JSON format
-f, --file-paths-only
output file paths only
-A, --absolute-paths
output absolute paths (defaults to relative)
-C, --disable-colored-output
disable colored output (colored by default)
-t, --filter-filetypes <FILTER_FILETYPES>
filter on filetype (defaults to all filetypes)
-H, --disable-hyperlinks
disable hyperlinks in output (defaults to false)
-D, --disable-devicons
disable devicons in output (defaults to false)
-h, --help
Print help
-V, --version
Print version
Upgrading gg
You may upgrade gg to its latest version by running:
gg upgrade
Upgrade the crate to its latest version
Usage: gg upgrade [OPTIONS]
Options:
-f, --force Optional flag for force upgrade
-h, --help Print help
https://github.com/user-attachments/assets/8620a805-4b2a-498e-a0a0-e8b6835bc9cd
Examples
Basic usage
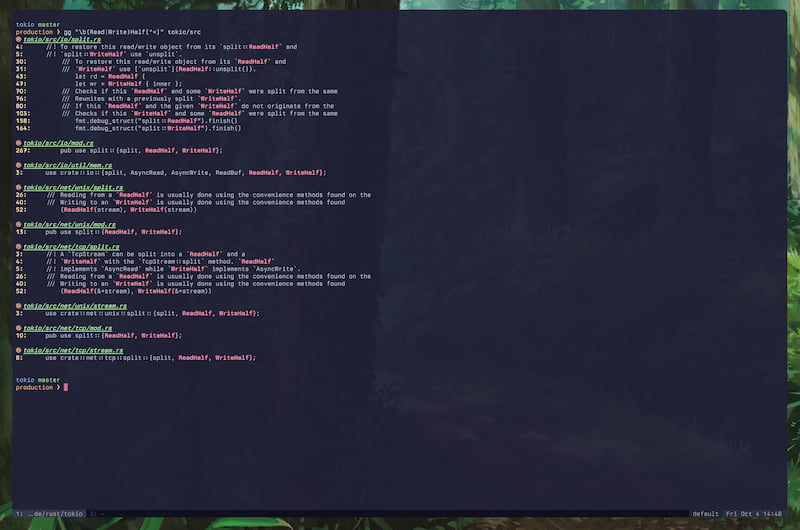
❯ gg "\b(Read|Write)Half[^<]" tokio/src
JSON output
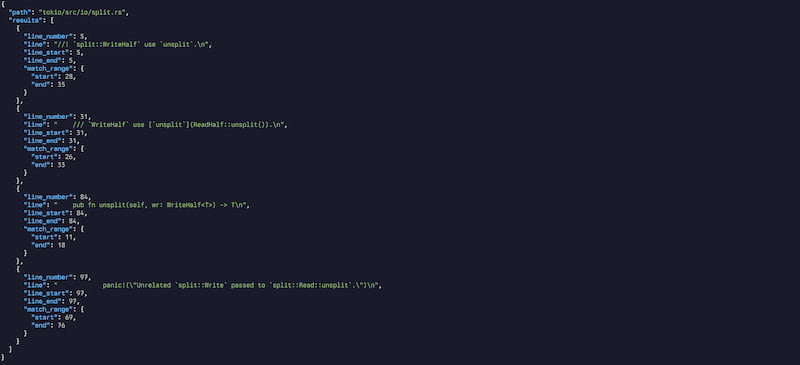
❯ gg --json unsplit tokio/src | jq
Filenames only
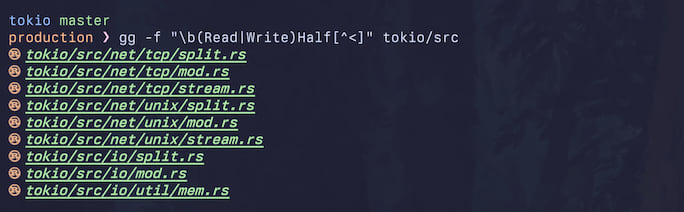
❯ gg -f "\b(Read|Write)Half[^<]" tokio/src
Notes
This lightweight utility is largely based on a couple of crates from the extraordinary ripgrep tool. Its aim is to provide a minimal and lightweight version that can be easily integrated in other programs for search-related purproses.
Dependencies
~9–18MB
~309K SLoC