1 unstable release
| 0.3.0 | Apr 17, 2024 |
|---|
#25 in #table-column
490KB
2.5K
SLoC
Placeholder
Simple, declarative data seeding for PostgreSQL
Important: Placeholder is in quite the alpha state and still very feature-incomplete.
Placeholder strives to make generating, reading, and maintaining fixture data a pleasant experience by exposing an expressive DSL that offers a lot more power than JSON or YML can while also not requiring you to set up language runtimes, factory classes, etc.
See the corresponding VS Code extension (also in an alpha state) for syntax highlighting examples.
Contents
Overview
Placeholder syntax is primarily inspired by SQL and, at a glance, allows you to group column & value pairs into records organized by table and, optionally, by schema if necessary.
Current language constructs include:
- Schema and table grouping declarations with optional aliases
- Anonymous & named records
- Primitive literal values: booleans, numbers, and text strings
- References to previous columns in the same record or named records in either the same or any other table
- Inline comments
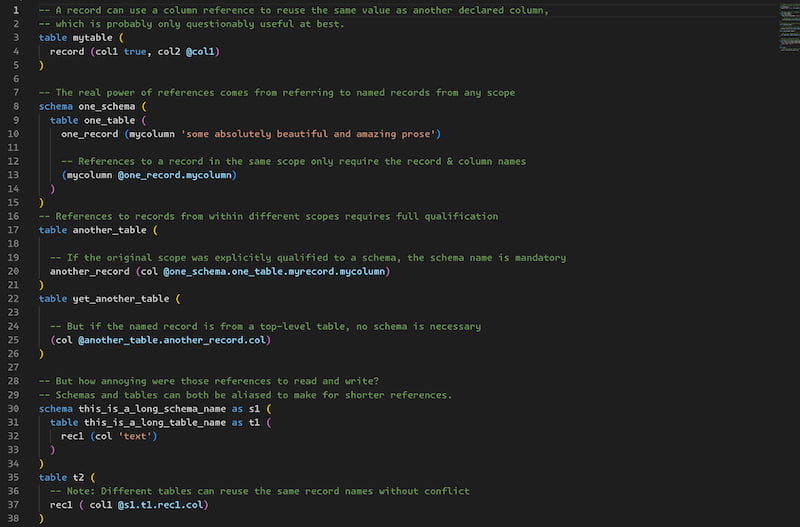
References are primarily what sets Placeholder apart from other declarative formats (eg. JSON), as they allow you to succinctly refer to values declared elsewhere or values returned from the database, such as autogenerated primary keys!
Other expressive constructs are planned that would further differentiate Placeholder, including:
- Mixins to define sets of values that can be included in a record, similar to 'traits' from factory bot
- Default values to apply to records in a table
- Series, etc. to create multiple records from a range or discrete list of values
General syntax
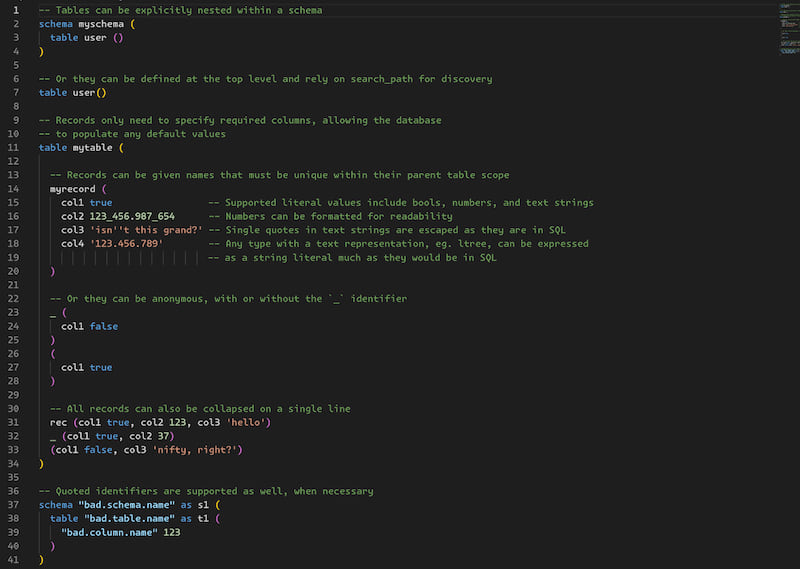
Referencing records
Installation
Placeholder currently must be compiled from source but precompiled
binaries for common platforms should be available soon and
ideally it should be installable via cargo soon as well.
Usage
Placeholder is designed to be easy to use.
Run hldr --help or hldr -h to see usage and all available options.
USAGE:
hldr [OPTIONS]
OPTIONS:
-c, --database-conn <CONN> Database connection string, either key/value pair or URI style
--commit Commit the transaction
-f, --data-file <DATA-FILE> Path to the .hldr data file to load [default: place.hldr if not
specified in options file]
-h, --help Print help information
-o, --opts-file <OPTS-FILE> Path to the optional .toml options file [default: hldr-opts.toml]
-V, --version Print version information
Options
Ultimately, there are 3 things to care about.
1. The data file to load
By default, hldr will look for a file called place.hldr to load,
but any other file can be loaded with the --data-file <path> or -f <path> option.
# Load the `place.hldr` file by default
$ hldr
# Or specify a different file
$ hldr --data-file example.hldr
$ hldr -f ../example.hldr
2. The database connection
To specify database connection details, pass either key-value pair or
URI-style string via --database-conn or -c.
For available options, see the
postgres driver docs.
In general, options are similar to libpq.
# URI style
$ hldr --database-conn "postgresql://user:password@host:port/dbname"
$ hldr -c "postgresql://user:password@host:port/dbname"
# Key/value style - useful when including `options` eg. to set custom search path
$ hldr --database-conn "user=me password=passy options='-c search_path=schema1,schema2'"
$ hldr -c "user=me password=passy options='-c search_path=schema1,schema2'"
3. Whether the transaction should be committed or rolled back
By default hldr rolls back the transaction to encourage dry-runs,
so pass the --commit flag to override that behavior.
$ hldr
Rolling back changes, pass `--commit` to apply
$ hldr --commit
Committing changes
The options file
Specifying command-line options can be convenient (eg. when using environment variables on CI/CD) but can be especially tedious for local development.
To make life easier, the database connection and default file can be
specified in a hldr-opts.toml file.
# hldr-opts.toml
#
# None of these values are required, and if supplied they will be overridden
# by any command-line options present
data_file = "../some-custom-file.hldr"
database_conn = "user=me password=passy options='-c search_path=schema1,schema2'"
If for whatever reason hldr-opts.toml is a disagreeable name,
a custom options file can be specified.
$ hldr --opts-file ../path/to/file.toml
$ hldr -o ../path/to/file.toml
Important: As this file can be environment-dependent and contain sensitive details, it should not be checked into version control.
Features
Literal values
Currently, there are only literal values for booleans, numbers, and strings.
hldr currently parses all values as strings and passes them to Postgres
using the simple query
protocol so that Postgres can convert values to their appropriate types.
Important: This means that hldr does not protect against SQL injection
from string values, though switching to extended query protocol is on the horizon.
Booleans
Boolean values must be either true or false.
Unlike SQL, values like TRUE or f are not supported.
Numbers
Numbers can be integer or floating point values - Placeholder does not distinguish
between them or attempt to figure out their size.
They are passed as strings and Postgres coerces them to the right type
on a per-column basis, and they can be pretty-formatted like 1_000 or 10_00.00_01
as long as there are not consecutive underscores, adjacent underscores & decimals, or
trailing underscores.
Strings
Text strings are single-quoted as they are in SQL and can be used to represent char,
varchar, text, or any other type such as arrays, timestamps, or even custom types
that can be represented as text.
For example, an array of integers would currently be written as '{1, 2, 3}'.
Escaping a single quote is the same as in SQL - just double it up and 'you''ll be fine'.
C-style escape strings (eg. E'won\'t work') are not currently supported.
Comments
Comments, like SQL, begin with -- and can either be newline or trailing comments.
Block comments are currently not supported but will be added in the future.
-- A newline comment
table (
record (
column value -- A trailing comment
)
)
Quoted identifiers
Schema, table, and column names follow Postgres rules in that they must be
double-quoted if they contain otherwise invalid identifier characters, share the
same name as keywrods, etc.
Even when unquoted, however, they are passed to the database as quoted identifiers,
meaning MyTable will be passed as "MyTable" so that it is not automatically
lowercased by Postgres.
schema "schema name with whitespace" (
table "table" (
"the answer" 41
)
table OtherTable ()
)
Named records
Records themselves can either be given a name, or they can be anonymous. Naming records allows their columns (even those populated by the database and not declared in the file) to be referenced in other records.
table person (
-- A named record
kevin (
name 'Kevin'
)
-- Anonymous records
_ (name 'A Different Kevin')
(name 'Yet Another Kev')
)
table name (
-- Record names only need to be unique within the given table
kevin (
value 'Kevin'
origin 'Irish'
derives_from 'Caoimhín'
)
)
References
Naming records allows them to be referenced elsewhere in the file, whether referencing a declared column or a column populated by default in the database.
There are several supported reference formats:
| Format | Example | Will Look For |
|---|---|---|
| Schema-qualified | @myschema.mytable.record.column |
A previously-declared record in a table explicitly nested under a schema |
| Table-qualified | @mytable.record.column |
A previously-declared record in a top-level table not nested under a schema |
| Record-qualified | @record.column |
A previously-declared record in the same table scope as the current record being declared |
| Column-qualified | @column |
A previously-declared column in the same record being declared (note: the column being referenced is not required to be a literal value; it can be be another reference to a column or other record entirely) |
Aliases
Schemas and tables can also have aliases to help shorten qualified references, in which case references must use those aliases instead of the full names. Note: Record-qualified references from within the same table scope still do not need to use the name or aliases.
table person as p (
p1 ( name 'Person 1' )
-- References within the same scope do not NEED to qualify
( name @p1.name )
-- But they can if desired. If this table was nested within a schema,
-- the schema name would be required as well.
( name @p.p1.name )
)
table pet (
-- The table alias is REQUIRED when referencing from another scope.
( person_id @p.p1.id )
)
Planned features
See issues marked as enhancements for planned features.
Dependencies
~10–20MB
~278K SLoC