15 releases (2 stable)
| 1.1.0 | Oct 26, 2024 |
|---|---|
| 1.0.0 | Jan 20, 2024 |
| 0.10.0 | Jun 11, 2023 |
| 0.9.0 | Jul 21, 2022 |
| 0.2.1 | Nov 30, 2019 |
#5 in Caching
83,199 downloads per month
Used in 85 crates
(35 directly)
350KB
1K
SLoC
ustr
Fast, FFI-friendly string interning.
A Ustr (Unique str) is a lightweight handle representing a static,
immutable entry in a global string cache, allowing for:
-
Extremely fast string assignment and comparisons.
-
Efficient storage. Only one copy of the string is held in memory, and getting access to it is just a pointer indirection.
-
Fast hashing ‒ the precomputed hash is stored with the string.
-
Fast FFI ‒ the string is stored with a terminating null byte so can be passed to C directly without doing the
CStringdance.
The downside is no strings are ever freed, so if you're creating lots and lots of strings, you might run out of memory. On the other hand, War and Peace is only 3MB, so it's probably fine.
This crate is based on OpenImageIO's
(OIIO) ustring
but it is not binary-compatible (yet). The underlying hash map implementation
is directy ported from OIIO.
Usage
use ustr::{Ustr, ustr};
// Creation is quick and easy using either `Ustr::from` or the `ustr` short
// function and only one copy of any string is stored.
let h1 = Ustr::from("hello");
let h2 = ustr("hello");
// Comparisons and copies are extremely cheap.
let h3 = h1;
assert_eq!(h2, h3);
// You can pass straight to FFI.
let len = unsafe {
libc::strlen(h1.as_char_ptr())
};
assert_eq!(len, 5);
// For best performance when using Ustr as key for a HashMap or HashSet,
// you'll want to use the precomputed hash. To make this easier, just use
// the UstrMap and UstrSet exports:
use ustr::UstrMap;
// Key type is always Ustr.
let mut map: UstrMap<usize> = UstrMap::default();
map.insert(u1, 17);
assert_eq!(*map.get(&u1).unwrap(), 17);
By enabling the "serde" feature you can serialize individual Ustrs or
the whole cache with serde.
use ustr::{Ustr, ustr};
let u_ser = ustr("serialization is fun!");
let json = serde_json::to_string(&u_ser).unwrap();
let u_de : Ustr = serde_json::from_str(&json).unwrap();
assert_eq!(u_ser, u_de);
Since the cache is global, use the ustr::DeserializedCache dummy object to
drive the deserialization.
ustr("Send me to JSON and back");
let json = serde_json::to_string(ustr::cache()).unwrap();
// ... some time later ...
let _: ustr::DeserializedCache = serde_json::from_str(&json).unwrap();
assert_eq!(ustr::num_entries(), 1);
assert_eq!(ustr::string_cache_iter().collect::<Vec<_>>(), vec!["Send me to JSON and back"]);
Calling from C/C++
If you are writing a library that uses ustr and want users to be able to create
Ustrs to pass to your API from C, add ustr_extern.rs to your crate and use
include/ustr.h or include/ustr.hpp for function declarations.
Changelog
Changes since 1.0.0
-
Add a bunch of trait implementations that make it easier to work with stringy types. Thanks to @kornelski.
-
Disable unused ahash features by default to fix compilation on
wasm-unknown-unknown. Thanks to @stephanemagnenat. -
Fix panic if string cache is empty and assorted miri warnings and errors. Thanks to @orzogc.
-
Bump versions of byteorder, lazy_static, ahash and add additional documentation. Thanks to @virtualritz.
Changes since 0.10
- Actually renamed
serializationfeature toserde
Changes since 0.9
- Fixed and issue that
would stop
Ustrfrom working onwasm32-unknown-unknown(contributed by bouk)
and thanks to virtualritz:
-
Ustr::get_cache()was renamed tocache() -
All dependencies were bumped to latest versions
-
All features were removed (there are good defaults) except for
serialization -
The
serializationfeature was renamed toserde -
ustrnow uses Rust 2021
Changes since 0.8
-
Add
existing_ustrfunction (contributed by macprog-guy)The idea behind this is to allow the creation of a
Ustronly when thatUstralready exists. This is particularly useful whenUstrs are being created using untrusted user input (say from a web server or API). In that case, by providing different values at each call we consume more and more memory eventually running out (DoS). -
Add implementation for
Ord(contributed by zigazeljko) -
Inlined a bunch of simple functions (contributed by g-plane)
-
Fixed tests to lock rather than relying on
RUST_TEST_THREADS=1(contributed by kornelski) -
Fixed tests to handle serialization feature properly when enabled (contributed by kornelski)
-
Added a check for a potential allocation failure in the allocator (contributed by kornelski)
-
Added
FromStrimpl (contributed by martinmr) -
Add
rustfmt.tomlto repo
Changes since 0.7
-
Update dependencies
The versions of
parking_lotandahashhave been updated. -
Space optimization with
NonNullThe internal pointer is now a
NonNullto take advanatge of layout optimizations inOptionetc. -
Add
as_cstr()methodAdded
as_cstr(&self) -> std::ffi::CStrto make it easier to interface with APIs that rely onCStr.
Changes since 0.6
-
Derive Ord for Ustr
So now you can sort a
VecofUstrs lexicographically.
Changes since 0.5
-
Added
From<Ustr>for&strThis
implmakes it easier to pass aUstrto methods expecting anInto<&str>.
Changes since 0.4
-
32-bit support added
Removed the restriction to 64-bit systems and fixed a bug relating to pointer maths. Thanks to agaussman for bringing it up.
-
Miri leak checks re-enabled
Thanks to RalfJung for pointing out that Miri now ignores "leaks" from statics.
-
PartialOrdis now lexicographic -
Thanks to macprog-guy for the PR implementing PartialOrd by deferring to
&str. This will be slower than the previous derived implementation which just did a pointer comparison, but is much less surprising.
Changes since 0.3
-
Added Miri to CI tests
Miri sanity-checks the unsafe parts of the code to guard against some types of UB.
-
Switched to ahash as the default hasher
Ahash is a fast, non-cryptographic pure Rust hasher. Pure Rust is important to be able to run Miri and ahash benchmarks the fastest I could find. The old
fasthash/cityhashis available by enabling--features=hashcity
Changes since 0.2
-
Serde support
Ustrcan now be serialized with Serde when enabling--features=serialization. The global string cache can also be serialized if you really want to. -
Switched to
parking_lot::Mutexas default synchronizationSpinlocks have been getting a bad rap recently so the string cache now uses
parking_lot::Mutexas the default synchronization primitive.spin::Mutexis still available behind the--features=spinlockfeature gate if you really want that extra 5% speed. -
Cleaned up
unsafeDid a better job of documenting the invariants for the unsafe blocks and replaced some blind additions with checked_add() and friends to avoid potential (but very unlikely) overflow.
-
Compared to
string-cachestring-cache provides a global cache that can be created at compile time as well as at run time. Dynamic strings in the cache appear to be reference-counted so will be freed when they are no longer used, while
Ustrs are never deleted.Creating a
string_cache::DefaultAtomis much slower than creating aUstr, especially in a multi-threaded context. On the other hand if you can just bake all yourAtoms into your binary at compile-time this wouldn't be an issue. -
Compared to
string-internerstring-interner gives you individual
Internerobjects to work with rather than a global cache, which could be more flexible. It's faster to create than string-cache but still significantly slower thanUstr.
Speed
Ustrs are significantly faster to create than string-interner or
string-cache. Creating 100,000 cycled copies of ~20,000 path strings of the
form:
/cgi-bin/images/admin
/modules/templates/cache
/libraries/themes/wp-includes
... etc.
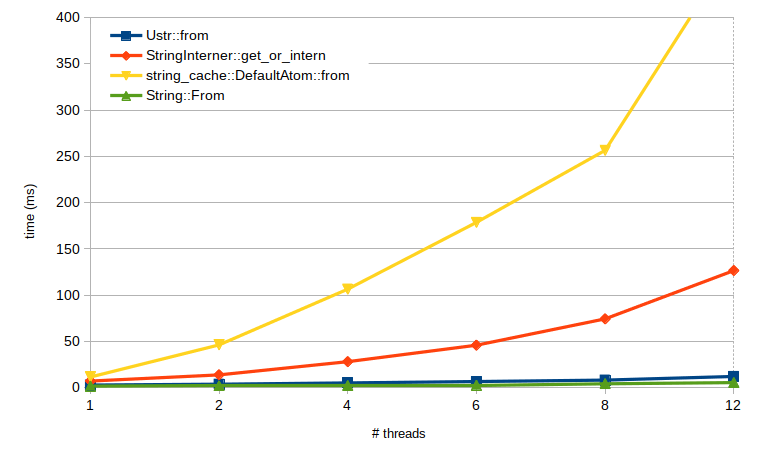
Why?
It is common in certain types of applications to use strings as identifiers,
but not really do any processing with them. To paraphrase from OIIO's ustring
documentation:
Compared to standard strings, Ustrs have several advantages:
-
Each individual
Ustris very small -- in fact, we guarantee that aUstris the same size and memory layout as an ordinary *u8. -
Storage is frugal, since there is only one allocated copy of each unique character sequence, throughout the lifetime of the program.
-
Assignment from one
Ustrto another is just copy of the pointer; no allocation, no character copying, no reference counting. -
Equality testing (do the strings contain the same characters) is a single operation, the comparison of the pointer.
-
Memory allocation only occurs when a new
Ustris constructed from raw characters the first time ‒ subsequent constructions of the same string just finds it in the canonial string set, but doesn't need to allocate new storage. Destruction of aUstris trivial, there is no de-allocation because the canonical version stays in the set. Also, therefore, no user code mistake can lead to memory leaks.But there are some problems, too. Canonical strings are never freed from the table. So in some sense all the strings "leak", but they only leak one copy for each unique string that the program ever comes across. Creating a
Ustris slower thanString::from()on a single thread, and performance will be worse if trying to create manyUstrs in tight loops from multiple threads due to lock contention for the global cache.
On the whole, Ustrs are a really great string representation
-
if you tend to have (relatively) few unique strings, but many copies of those strings;
-
if you tend to make the same strings over and over again, and if it's relatively rare that a single unique character sequence is used only once in the entire lifetime of the program; ‒ if your most common string operations are assignment and equality testing and you want them to be as fast as possible;
-
if you are doing relatively little character-by-character assembly of strings, string concatenation, or other "string manipulation" (other than equality testing).
Ustrs are not so hot:
-
if your program tends to have very few copies of each character sequence over the entire lifetime of the program;
-
if your program tends to generate a huge variety of unique strings over its lifetime, each of which is used only a short time and then discarded, never to be needed again;
-
if you don't need to do a lot of string assignment or equality testing, but lots of more complex string manipulation.
Safety and Compatibility
This crate contains a significant amount of unsafe but usage has been checked and is well-documented. It is also run through Miri as part of the CI process.
I use it regularly on 64-bit systems, and it has passed Miri on a 32-bit system as well, bit 32-bit is not checked regularly. If you want to use it on 32-bit, please make sure to run Miri and open and issue if you find any problems.
License
BSD+ License
Copyright © 2019—2024 Anders Langlands
Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met:
-
Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer.
-
Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
Subject to the terms and conditions of this license, each copyright holder and contributor hereby grants to those receiving rights under this license a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable (except for failure to satisfy the conditions of this license) patent license to make, have made, use, offer to sell, sell, import, and otherwise transfer this software, where such license applies only to those patent claims, already acquired or hereafter acquired, licensable by such copyright holder or contributor that are necessarily infringed by:
(a) their Contribution(s) (the licensed copyrights of copyright holders and non-copyrightable additions of contributors, in source or binary form) alone; or
(b) combination of their Contribution(s) with the work of authorship to which such Contribution(s) was added by such copyright holder or contributor, if, at the time the Contribution is added, such addition causes such combination to be necessarily infringed. The patent license shall not apply to any other combinations which include the Contribution.
Except as expressly stated above, no rights or licenses from any copyright holder or contributor is granted under this license, whether expressly, by implication, estoppel or otherwise.
DISCLAIMER
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDERS OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
Contains code ported from OpenImageIO, BSD 3-clause license.
Contains a copy of Max Woolf's Big List of Naughty Strings, MIT license.
Contains some strings from SecLists, MIT license.
Dependencies
~1.3–6.5MB
~29K SLoC