5 releases (breaking)
| new 0.5.0 | Apr 20, 2025 |
|---|---|
| 0.4.0 | Apr 6, 2025 |
| 0.3.0 | Apr 1, 2025 |
| 0.2.0 | Mar 31, 2025 |
| 0.1.0 | Mar 28, 2025 |
#185 in Web programming
641 downloads per month
1.5MB
6K
SLoC
Extracts URLs from OSINT Archives for Security Insights.
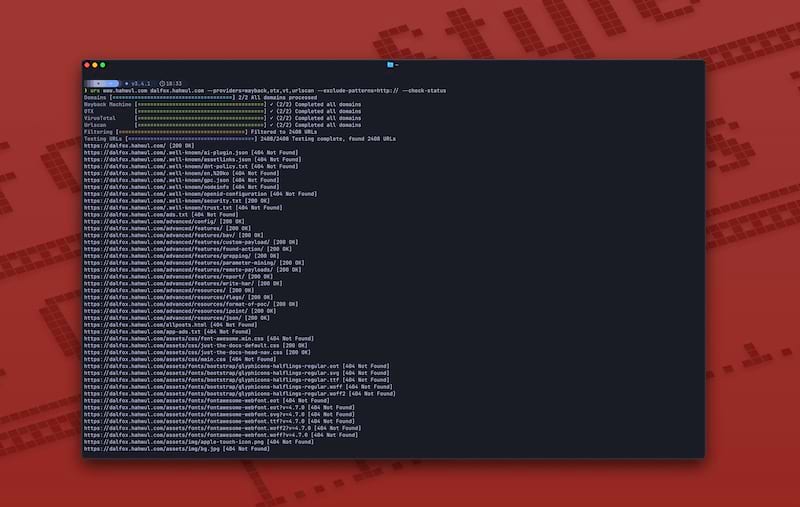
Urx is a command-line tool designed for collecting URLs from OSINT archives, such as the Wayback Machine and Common Crawl. Built with Rust for efficiency, it leverages asynchronous processing to rapidly query multiple data sources. This tool simplifies the process of gathering URL information for a specified domain, providing a comprehensive dataset that can be used for various purposes, including security testing and analysis.
Features
- Fetch URLs from multiple sources in parallel (Wayback Machine, Common Crawl, OTX)
- Filter results by file extensions, patterns, or predefined presets (e.g., "no-image" to exclude images)
- Support for multiple output formats: plain text, JSON, CSV
- Output results to the console or a file, or stream via stdin for pipeline integration
- URL Testing:
- Filter and validate URLs based on HTTP status codes and patterns.
- Extract additional links from collected URLs
Installation
From Cargo (Recommended)
cargo install urx
From Homebrew (Tap)
brew tap hahwul/urx
brew install urx
From Source
git clone https://github.com/hahwul/urx.git
cd urx
cargo build --release
The compiled binary will be available at target/release/urx.
From Docker
Usage
Basic Usage
# Scan a single domain
urx example.com
# Scan multiple domains
urx example.com example.org
# Scan domains from a file
cat domains.txt | urx
Options
Usage: urx [OPTIONS] [DOMAINS]...
Arguments:
[DOMAINS]... Domains to fetch URLs for
Options:
-c, --config <CONFIG> Config file to load
-h, --help Print help
-V, --version Print version
Output Options:
-o, --output <OUTPUT> Output file to write results
-f, --format <FORMAT> Output format (e.g., "plain", "json", "csv") [default: plain]
--merge-endpoint Merge endpoints with the same path and merge URL parameters
Provider Options:
--providers <PROVIDERS> Providers to use (comma-separated, e.g., "wayback,cc,otx,vt,urlscan") [default: wayback,cc,otx]
--subs Include subdomains when searching
--cc-index <CC_INDEX> Common Crawl index to use (e.g., CC-MAIN-2025-13) [default: CC-MAIN-2025-13]
--vt-api-key <VT_API_KEY> API key for VirusTotal (can also use URX_VT_API_KEY environment variable)
--urlscan-api-key <URLSCAN_API_KEY> API key for Urlscan (can also use URX_URLSCAN_API_KEY environment variable)
--include-robots Include robots.txt discovery
--include-sitemap Include sitemap.xml discovery
Display Options:
-v, --verbose Show verbose output
--silent Silent mode (no output)
--no-progress No progress bar
Filter Options:
-p, --preset <PRESET>
Filter Presets (e.g., "no-resources,no-images,only-js,only-style")
-e, --extensions <EXTENSIONS>
Filter URLs to only include those with specific extensions (comma-separated, e.g., "js,php,aspx")
--exclude-extensions <EXCLUDE_EXTENSIONS>
Filter URLs to exclude those with specific extensions (comma-separated, e.g., "html,txt")
--patterns <PATTERNS>
Filter URLs to only include those containing specific patterns (comma-separated)
--exclude-patterns <EXCLUDE_PATTERNS>
Filter URLs to exclude those containing specific patterns (comma-separated)
--show-only-host
Only show the host part of the URLs
--show-only-path
Only show the path part of the URLs
--show-only-param
Only show the parameters part of the URLs
--min-length <MIN_LENGTH>
Minimum URL length to include
--max-length <MAX_LENGTH>
Maximum URL length to include
--strict
Enforce exact host validation (default)
Network Options:
--network-scope <NETWORK_SCOPE> Control which components network settings apply to (all, providers, testers, or providers,testers) [default: all]
--proxy <PROXY> Use proxy for HTTP requests (format: http://proxy.example.com:8080)
--proxy-auth <PROXY_AUTH> Proxy authentication credentials (format: username:password)
--insecure Skip SSL certificate verification (accept self-signed certs)
--random-agent Use a random User-Agent for HTTP requests
--timeout <TIMEOUT> Request timeout in seconds [default: 30]
--retries <RETRIES> Number of retries for failed requests [default: 3]
--parallel <PARALLEL> Maximum number of parallel requests per provider and maximum concurrent domain processing [default: 5]
--rate-limit <RATE_LIMIT> Rate limit (requests per second)
Testing Options:
--check-status Check HTTP status code of collected URLs [aliases: --cs]
--include-status <INCLUDE_STATUS> Include URLs with specific HTTP status codes or patterns (e.g., --is=200,30x) [aliases: --is]
--exclude-status <EXCLUDE_STATUS> Exclude URLs with specific HTTP status codes or patterns (e.g., --es=404,50x,5xx) [aliases: --es]
--extract-links Extract additional links from collected URLs (requires HTTP requests)
Examples
# Save results to a file
urx example.com -o results.txt
# Output in JSON format
urx example.com -f json -o results.json
# Filter for JavaScript files only
urx example.com -e js
# Exclude HTML and text files
urx example.com --exclude-extensions html,txt
# Filter for API endpoints
urx example.com --patterns api,v1,graphql
# Exclude specific patterns
urx example.com --exclude-patterns static,images
# Use Fileter Preset (similar to --exclude-extensions=png,jpg,.....)
urx example.com -p no-images
# Use specific providers
urx example.com --providers wayback,otx
# Use VirusTotal and URLScan with API keys
urx example.com --providers=vt,urlscan --vt-api-key=*** --urlscan-api-key=****
# Use VirusTotal and URLScan with environment variables for API keys
URX_VT_API_KEY=**** URX_URLSCAN_API_KEY=**** urx example.com --providers=vt,urlscan
# Extract URLs from robots.txt files
urx example.com --include-robots
# Extract URLs from sitemap
urx example.com --include-sitemap
# Include subdomains
urx example.com --subs
# Check status of collected URLs
urx example.com --check-status
# Extract additional links from collected URLs
urx example.com --extract-links
# Network configuration
urx example.com --proxy http://localhost:8080 --timeout 60 --parallel 10 --insecure
# Advanced filtering
urx example.com -e js,php --patterns admin,login --exclude-patterns logout,static --min-length 20
# HTTP Status code based filtering
urx example.com --include-status 200,30x,405 --exclude-status 20x
# Disable host validation
urx example.com --strict false
Integration with Other Tools
Urx works well in pipelines with other security and reconnaissance tools:
# Find domains, then discover URLs
echo "example.com" | urx | grep "login" > potential_targets.txt
# Combine with other tools
cat domains.txt | urx --patterns api | other-tool
Inspiration
Urx was inspired by gau (GetAllUrls), a tool that fetches known URLs from AlienVault's Open Threat Exchange, the Wayback Machine, and Common Crawl. While sharing similar core functionality, Urx was built from the ground up in Rust with a focus on performance, concurrency, and expanded filtering capabilities.
Contribute
Urx is open-source project and made it with ❤️ if you want contribute this project, please see CONTRIBUTING.md and Pull-Request with cool your contents.

Dependencies
~15–28MB
~398K SLoC