10 releases (6 breaking)
| 0.7.0 | Nov 16, 2024 |
|---|---|
| 0.6.2 | Oct 11, 2024 |
| 0.6.0 | Feb 20, 2024 |
| 0.3.0 | Dec 27, 2023 |
| 0.1.0 | Jun 2, 2023 |
#43 in Parser tooling
Used in rustemo-compiler
135KB
3K
SLoC
![]()
![]()
![]()
Rustemo is a LR/GLR parser generator for Rust.
Status: Fairly complete feature set. Very good test/docs coverage. Not yet optimized for speed so don't expect blazing performance.
Feedback is welcome!
Be sure to check Rustemo book. There you can find a detailed description and a comprehensive tutorial.
All features are covered with integration tests. So these can serve as a very good source of information.
There are also a few examples.
User fogarecious has contributed a simple tutorial geared towards Rustemo beginners so, though unofficial, this is also a good material to read while learning Rustemo.
Aspirations
-
Both LR and GLR parsing from the same grammar
E.g. start with GLR for easier development and refactor to LR for performance, or start from LR and move to GLR if your language needs more than 1 token of lookahead or is inherently ambiguous.
-
Usability and error reporting
Rustemo should be easy to use with sane defaults. Each error should be caught and explained with sufficient details. The docs should always be up-to-date and all docs examples should be tested by CI.
-
Clean separation of CFG grammar and semantic actions written in Rust
So a regular editors can be used for editing Rust code to its full potential. At the same time the syntax of the language is kept clean and existing grammars can be easily ported to Rustemo.
-
Syntax sugar for common patterns
E.g. zero-or-more(
*), one-or-more (+), optional(?), groups (()), multiple match with a separator etc. -
Clean separation between lexer, parser and builder
A parser asks a lexer for next tokens during parsing while telling the lexer what is expected due to the current parsing context. This avoids certain classes of lexical ambiguities. The parser calls builder to produce the result on each parser operation.
-
Flexibility
Default lexers and builders are provided/generated out-of-the box but the user can choose to write custom lexer and/or builder.
When a custom lexer/builder is provided Rustemo can be used to parse virtually any kind of sequence and also build any kind of output.
-
Inference of AST node types from the grammar
For the default built-in builder, AST node types and semantics actions are inferred from the grammar and auto-generated, but the user can introduce manual changes.
-
Zero-copy by default
Built-in builders should by default produce outputs by borrowing from the input.
-
High test coverage
There are a reasonable number of tests. I usually write tests before implementing each new feature (TDD). Since each feature is covered by tests these can serve as a good source of how-to information.
Small example
Let's start with the ambiguous grammar calc.rustemo:
E: E '+' E
| E '*' E
| Number
;
terminals
Number: /\d+/;
Add: '+';
Mul: '*';
This grammar cannot be accepted by LR(1) parser but is accepted by GLR. So let's create GLR parser for this grammar, and dot visualization of the parser automaton:
$ rcomp --dot --parser-algo glr calc.rustemo
Generating parser for grammar "calc.rustemo"
Writting dot file: "calc.dot"
LALR(1) automaton for this grammar has conflicts in states 5 and 6 but that's not a problem for GLR.
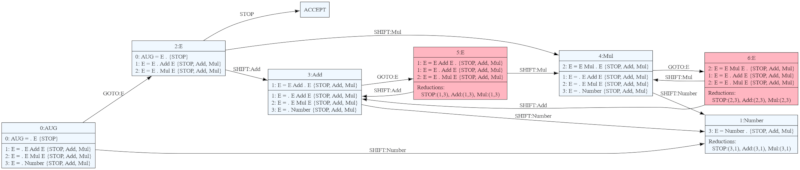
Let's now test our parser.
#![cfg(test)]
mod calc;
mod calc_actions;
use crate::calc::{CalcParser, DefaultBuilder};
use rustemo::Parser;
#[test]
fn test_glr() {
let forest = CalcParser::new().parse("2 + 3 * 4 + 1").unwrap();
// We have 5 possible solutions, see https://en.wikipedia.org/wiki/Catalan_number
assert_eq!(forest.solutions(), 5);
// Evaluate each tree from the forest
let results = forest
.into_iter()
.map(|tree| {
let mut builder = DefaultBuilder::new();
tree.build(&mut builder)
})
.collect::<Vec<_>>();
assert_eq!(results, vec![21, 15, 25, 15, 17]);
}
DefaultBuilder generated by rcomp use generated and manually tuned actions
from calc_actions. For more details see full tutorial in the Rustemo
book.
Now, let's make this grammar acceptable by LR parser. The easiest way to do it,
while keeping the grammar readable is to use Rustemo declarative disambiguation
to resolve shift-reduce conflicts thus making the parsing deterministic. For
this we specify that both operations are left associative and that * operation
has higher precedence:
E: E '+' E {left, 1}
| E '*' E {left, 2}
| Number
;
terminals
Number: /\d+/;
Add: '+';
Mul: '*';
It is now possible to generate parser using the default LR algorithm and the
default lalr-pager tables (an improved version of LALR, there is also a
standard lalr table support if needed, see rcomp --help):
$ rcomp calclr.rustemo
Generating parser for grammar "calclr.rustemo"
Let's test our LR grammar:
mod calclr;
mod calclr_actions;
use self::calclr::CalclrParser;
use rustemo::Parser;
#[test]
fn test_lr() {
let result = CalclrParser::new().parse("2 + 3 * 4 + 1").unwrap();
// As the parsing is deterministic now we have just 1 solution which is
// automatically evaluated using the default builder and provided actions
assert_eq!(result, 15);
}
This is just a glimpse of what is possible. For more information see the Rustemo book.
Roadmap (tentative)
v0.1.0
- LR parsing.
- Bootstrapping. Rustemo is implemented in itself.
- Built-in lexer for parsing strings. Support for custom lexers.
- Built-in builders: AST, generic CST, slice builder. Support for custom builders. Passing context to actions. See the tests .
- Actions providing AST build are auto-generated but can be manually modified. Manual modifications are preserved on code re-generation while new types/actions are added to the file. This allow for fast development while keeping full control over the AST.
- Regex-like syntax sugar. See the tests.
- Repetition modifiers (e.g. separator)
- Disambiguation filters: priorities, associativities.
- Rule/production meta-data. E.g. production kinds.
- CLI and API. A
rcompcompiler CLI is available that can be called on Rustemo grammars. Also, API enables integrating parser code generation into Rustbuild.rsscripts. See the calculator example or integration tests. - Tracking of position and reporting error with line/column.
- Support for a layout (comments, whitespaces given as CFG). It is implemented as a special grammar rule and parsed by the LR parser. Result is passed by context to actions which can do whatever they please. E.g. a generic tree builder keeps layout on the following tree leaf. See the tests.
- Detailed error reporting during grammar analysis and state machine building.
- Docs completed.
- First release to crates.io!
v0.2.0
- GLR parsing based on Right-Nulled GLR algorithm (RNGLR).
- Base Tomita's algorithm. Shared packed parse forest.
- Lazy tree extraction from forest.
- Calling arbitrary builder over extracted tree.
- Support for EMPTY productions through RN table entries (RNGLR algorithm).
- GLR docs
- Release to crates.io
Next releases until v1.0 (see CHANGELOG.md for the details)
- Forest iteration.
- Support for different parser table generators.
- Benchmark tests + performance optimizations.
- Greedy repetitions.
- Zero copy for built-in builders.
- Parenthesized groups. Still not sure if this is a good thing to have. Sometimes it can nicely reduce clutter but if used too much it lowers readability.
v1.0
- Grammars compositions. Grammars importing, rule inheritance etc.
- Better disambiguations (investigate dynamic).
- Visualizations/debugging of GLR parsing process.
Post v1.0
- Error recovery, e.g. an approach taken by tree-sitter.
- Incremental parsing (reparse just the changed part of the input).
- Elkhound style of LR/GLR switching.
- Tooling for working with Rustemo grammars (e.g. LSP server, plugins for popular editors).
License
Licensed under either of
- Apache License, Version 2.0, (LICENSE-APACHE or http://www.apache.org/licenses/LICENSE-2.0)
- MIT license (LICENSE-MIT or http://opensource.org/licenses/MIT)
Contribution
Unless you explicitly state otherwise, any contribution intentionally submitted for inclusion in the work by you, as defined in the Apache-2.0 license, shall be dual licensed as above, without any additional terms or conditions.
Please see Contributing guide in the docs for the details.
Credits
Bootstrapping approach and the idea of macro for loading the generated code are based on the approach taken in the LALRPOP project.
Similar projects
The architecture and the general idea of Rustemo is loosely based on a similar project for Python, called parglare, I've started several years ago.
I have found a lot of inspiration and ideas in the following projects:
- LALRPOP - LR(1) parser generator for Rust. This project is the most similar to Rustemo so I've found there a lot of nice ideas.
- Nom - Parser combinator library. Nice architecture and nicely designed traits.
- pest - PEG parser for Rust. Seems nice and well maintained.
Why this name?
Rustemo is pronounced the same as Serbian word "растемо" which means "we grow". The name is a tribute to the awesome and ever growing Rust community.
Dependencies
~3–11MB
~114K SLoC