462 releases (94 breaking)
| new 0.95.6 | Apr 17, 2025 |
|---|---|
| 0.94.0 | Apr 16, 2025 |
| 0.89.0 | Mar 31, 2025 |
| 0.64.4 | Dec 20, 2024 |
| 0.6.2 | Jul 31, 2024 |
#46 in Magic Beans
10,258 downloads per month
Used in proof-of-sql-planner
3MB
69K
SLoC
Proof of SQL

![]()
Proof of SQL is a high performance zero knowledge (ZK) prover developed by the Space and Time team, which cryptographically guarantees SQL queries were computed accurately against untampered data. It targets online latencies while proving computations over entire chain histories, an order of magnitude faster than state-of-the art zkVMs and coprocessors.
As the first sub-second ZK prover, the protocol can execute analytic queries over 100k-row tables in less than a second on a single GPU (see benchmarks below). It can aggregate over millions of rows of indexed data within Ethereum block time on a single NVIDIA T4. The protocol is designed to support both onchain and offchain verification, leveraging a novel commitment scheme which significantly lowers gas fees with onchain verification.
Using Proof of SQL, developers can compute over both onchain and offchain datasets in a trustless manner, proving the result back to their smart contract (or offchain verifier) just-in-time during a transaction to power more sophisticated DeFi protocols with data-driven contracts. Proof of SQL can be integrated into any SQL database (such as Google BigQuery), centralized or decentralized, and is already securing some of the most prominent Web3 apps, financial institutions, and enterprises.
Contributing
Proof of SQL is in active development, and not all SQL functions are supported yet. Proof of SQL is most powerful as a community-driven project. We hope to foster a large group of contributors that can help maintain, improve, and use this project to create a trustless and data-driven future. Please create an Issue, file a PR, or reach out via Discord if you want to add a SQL feature, integrate into another ZK solution, use this in your project, or anything else! Check out our guidelines: CONTRIBUTING.md.
For Developers
Get started with Proof of SQL by using the published crate on crates.io or clone the repo and check out the examples. Check out the following sections of the README:
Setup
Prerequisites
- Linux
x86_64(NOTE: Most of the codebase should work for most rust targets. However, proofs are accelerated using NVIDIA GPUs, so other targets would run very slowly and may require modification.) - NVIDIA GPU & Drivers (Strongly Recommended)
- lld (
sudo apt install lld) - clang (
sudo apt install clang) - Rust 1.81.0
Workaround for non-Linux and/or non-GPU machines.
- Workaround #1: enable the CPU version of Blitzar by setting the
BLITZAR_BACKENDenvironment variable. Example:export BLITZAR_BACKEND=cpu cargo test --all-features --all-targets - Workaround #2: disable the
blitzarfeature in the repo. Examplecargo test --no-default-features --features="arrow cpu-perf"
Examples
Proof of SQL comes with example code demonstrating its usage. You can find the examples in the crates/proof-of-sql/examples folder. Below are explanations of how to run some of these examples:
"Hello World" Example
The "Hello World" example demonstrates generating and verifying a proof of the query SELECT b FROM table WHERE a = 2 for the table:
| a | b |
|---|---|
| 1 | hi |
| 2 | hello |
| 3 | there |
| 2 | world |
Run
cargo run --example hello_world
Note
To run this example without the blitzar (i.e CPU only) feature:
cargo run --example hello_world --no-default-features --features="rayon test"
Output
Warming up GPU... 520.959485ms
Loading data... 3.229767ms
Parsing Query... 1.870256ms
Generating Proof... 467.45371ms
Verifying Proof... 7.106864ms
Valid proof!
Query result: OwnedTable { table: {Ident { value: "b", quote_style: None }: VarChar(["hello", "world"])} }
For a detailed explanation of the example and its implementation, refer to the README and source code in hello_world/main.rs.
CSV Database Example
The CSV Database example demonstrates an implementation of a simple CSV-backed database with Proof of SQL capabilities.
To install the example:
cargo install --example posql_db --path crates/proof-of-sql #TODO: update once this is published to crates.io
For detailed usage instructions and examples of how to create, append to, prove, and verify queries in the CSV-backed database, refer to the README and source code in posql_db/main.rs.
Benchmarks
Proof of SQL is optimized for speed and efficiency. Here's how it's so fast:
- We use native, precomputed commitments to the data. In other words, when adding data to the database, we compute a "digest" of the data, which effectively "locks in" the data. Instead of using a merkle tree based commitment, like those use in most blockchains, we use the commitment scheme that is inherent to Proof of SQL itself.
- SQL is conducive to a natural arithmetization, meaning that there is very little overhead compared with other proof systems that are designed around instructions/sequential compute. Instead, Proof of SQL is designed from the ground up with data processing and parallelism in mind.
- We use GPU acceleration on the most expensive cryptography in the prover. We use Blitzar as our acceleration framework.
Setup
We run benchmarks using both a machine with multiple NVIDIA A100 GPUs (NC A100 v4-series Azure VM) and a machine with a single NVIDIA T4 GPU (NCasT4_v3-series Azure VM).
To run these benchmarks we first generate a large, randomly-filled table of data such as the following:
| a (BIGINT) | b (BIGINT) | c (VARCHAR) |
|---|---|---|
| 17717 | -1 | Z |
| 11651 | -3 | W |
| -9563 | -2 | dS |
| -6435 | -2 | x |
| -8338 | -1 | jI |
| 12420 | -2 | DX |
| 11546 | -3 | |
| 18292 | 2 | |
| 6500 | -1 | C |
| 16219 | 2 | D5 |
Then, we run the following 3 queries against these data, prove, and verify the results:
- Query #1 -
SELECT b FROM table WHERE a = 0 - Query #2 -
SELECT * FROM table WHERE ((a = 0) or (b = 1)) and (not (c = 'a')) - Query #3 -
SELECT b, SUM(a) as sum_a, COUNT(*) as c FROM table WHERE (c = 'a' OR c = 'b') AND b > 0 GROUP BY b
An example result for the 3rd query looks like this:
b |
sum_a |
c |
|---|---|---|
| 1 | -45585 | 301 |
| 2 | -137574, | 300 |
| 3 | -107073 | 282 |
Results
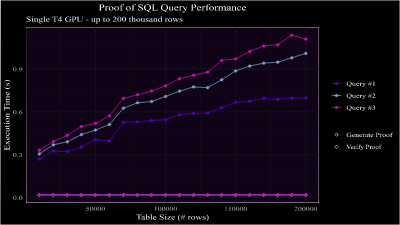
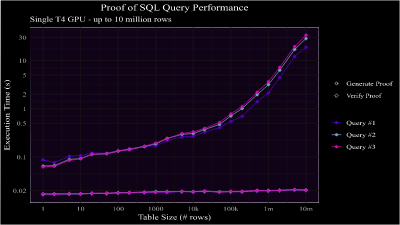
The results are shown in the graphs below for the T4 machine and the A100 machine on all three of the queries listed above. Broadly the results are:
- A query against 200 thousand rows of data can be proven in sub-second time.
- A query against 100 million rows of data can be proven in roughly a minute.
- Verification time is roughly 20ms across the board.
Supported SQL Syntax
See the SQL specification for more details. Broadly, we support the following with more SQL features being added quickly:
SELECT ... WHEREGROUP BY- Comparison operations:
=,>=,<=, etc. - Logical operations:
AND,OR,NOT. - Numerical operations
+,-,*. - Aggregations:
SUM,COUNT - Data Types:
BOOLEAN, Integer types,VARCHAR,DECIMAL75,TIMESTAMP.
Roadmap
Proof of SQL is in active development. Here are some items that we are currently working on. We are happy to receive feedback on additional features that the community requests.
- Expanded SQL support - in particular, multi-table queries (like JOIN) and subqueries
- Cluster scale proofs - this means faster proofs over larger tables!
- Solidity (EVM) verifier - for more efficient onchain verification.
- A novel commitment scheme - while we support a variety of commitment schemes, we are developing a commitment scheme specifically for database operations, ensuring lower-gas onchain verification.
We are also currently undergoing robust security audits. Keep this in mind as you use this code.
Protocol Overview
See the Space and Time Whitepaper for a more in depth explanation. We will also be adding more technical documentation to this repo soon.
We created this protocol with a few key goals. First, it needs to be super fast for data processing, both for verification and round-trip execution. This requires a design that is built from the ground up, as opposed to using arbitrary zkVMs. Second, we made it very developer-friendly. Using SQL, the most popular data query language, ensures a familiar experience for anyone building data-focused applications, or sophisticated data-driven contracts. Finally, our protocol is designed to handle complex data processing, not just simple serial compute or data retrieval.
In this protocol, there are two main roles: the client sending the query (Verifier) and the database service returning the result (Prover). Of course, the Verifier doesn't always have to send the query; it can be any client, such as a smart contract, a dapp frontend, or a laptop . This setup is crucial for applications with limited compute or storage but still requires a security guarantee that data analytics are correctly executed and the data remains unaltered. The Prover handles heavy computations, while the Verifier is lightweight, suitable for client devices or smart contracts with limited resources.
A key architectural feature is the concept of a commitment, or digest. To ensure data integrity, the Verifier maintains this commitment to detect any tampering. Think of it as a digital fingerprint—a lightweight digest representing the data in the table.
Data Ingestion
The initial interaction between the Verifier and the Prover involves data ingestion. In this process, when a service or client submits data for database inclusion, it first passes through the Verifier. Here, the Verifier generates (or updates) a commitment containing sufficient information to safeguard against tampering throughout the protocol. Once this commitment is established, the Verifier forwards the data to the database for storage, while retaining the commitment for future reference.
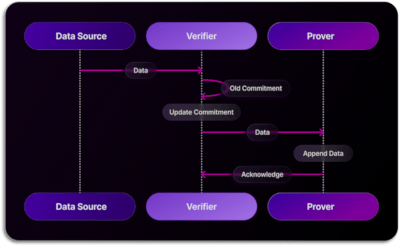
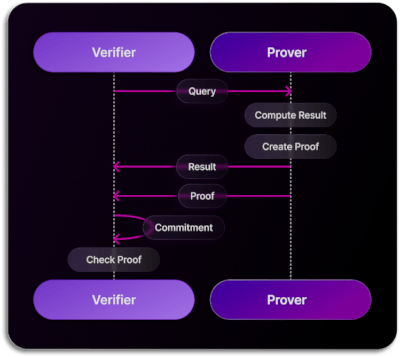
Query Request
The second interaction involves query requests, where the Verifier seeks data analytics on Prover-held data. When a service, client, or Verifier initiates a query request, it sends the request to the Prover. Here, the Prover parses the query, computes the result, and generates a proof, sent alongside the result to the Verifier, which is maintaining the commitment. The Verifier, armed with the proof and commitment, can verify the Prover's result against the query request.
License
Proof of SQL is licensed under the Decentralized Open Software License 1.0. Please see the LICENSE file for details.
Dependencies
~24–40MB
~680K SLoC