4 releases (2 breaking)
| 0.3.1 | Aug 31, 2021 |
|---|---|
| 0.3.0 | Mar 10, 2021 |
| 0.2.0 | Nov 14, 2020 |
| 0.1.0 | Oct 30, 2020 |
#954 in Data structures
89KB
2K
SLoC
![]()
Package implement persistent array using a variant of rope data structure.
Why would you want it ?
Array is implemented as std::vec in rust-standard library.
For most cases that should be fine. But when we start working with arrays
that are super-large and/or step into requirements like non-destructive
writes and concurrent access, we find std::vec insufficient.
im is a popular alternative, but has insert() and delete()
penalties similar to std::vec for large arrays. While most implementation
prefer to use RRB-Tree, ppar is based on Rope data structure.
Here is a quick list of situation that might require using ppar.
- When array size is too large with repeated insert and remove operation.
- When shared ownership is required.
- When shared ownership across concurrent threads.
- To support undo/redo operation for array modifications.
- When splitting up of array and/or joining arrays are frequently done.
- Lazy clone of array using copy-on-write.
Check out our performance metric
Algorithm
Fundamentally, it can be viewed as a binary-tree of array-blocks, where
each leaf-node is a contiguous-block of type T items, while intermediate
nodes only hold references to the child nodes - left and right.
To be more precise, intermediate nodes in the tree are organised similar
to rope structure, as a tuple of (weight, left, right) where weight is
the sum of all items present in the leaf-nodes under the left-branch.
A list of alternatives can be found here. If you find good alternatives please add it to the list and raise a PR.
If you are planning to use ppar for your project, do let us know.
Goals
- Vector parametrized over type T.
- Immutable / Persistent collection of Vector.
- CRUD operation, get(), set(), delete(), insert(), all are persistent.
- Convert from Vec to ppar::Vector.
- Convert from ppar::Vector to Vec.
- Thread safe operations.
- std::vec::Vec like mutable API.
- Iteration over collection, item-wise, chunk-wise, reverse.
- Deduplication.
- Membership.
- Joining collections, splitting into collections.
- Partial collection.
- Extending collection.
- Queue operations, like pop(), push().
- Functional ops, like filter, map, reduce.
- Sort and search operations.
- Trait implementations.
- Clone
- Eq, PartialEq, Ord, PartialOrd
- Extend
- From, FromIterator, IntoIterator
- Hash
- Index, IndexMut
- Write
- Parallel iteration with rayon.
- Fuzzy tested.
The basic algorithm is fairly tight. Contributions are welcome to make the
ppar::Vector type as rich as std::vec::Vec and
im::Vector.
Performance metric
On a 2008 core2-duo machine with 8GB RAM. The measurements are taken using the following command and all the numbers are op Vs latency.
cargo run --release --bin perf --features=perf -- --load 100000 --ops 10000
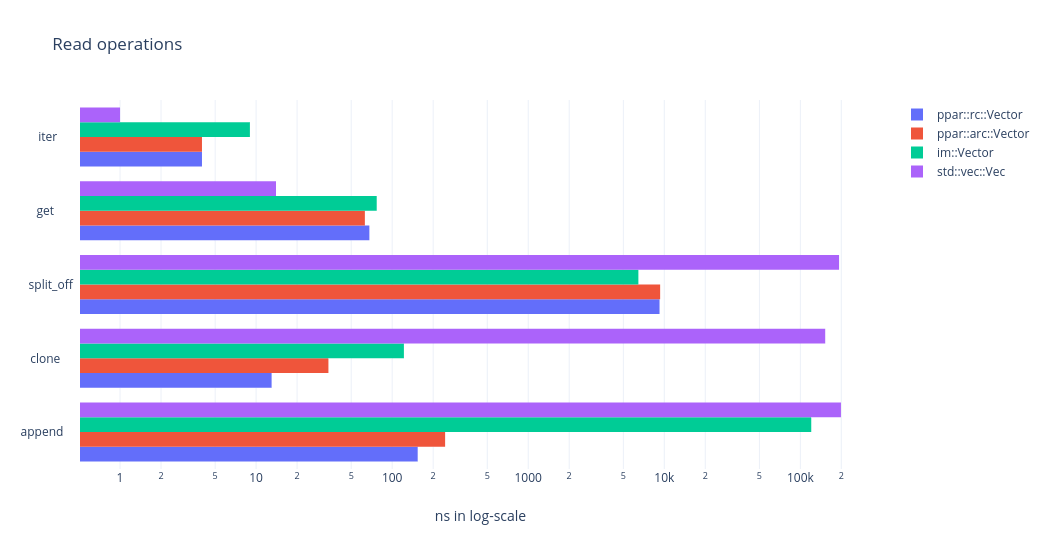 Lower numbers are better
Lower numbers are better
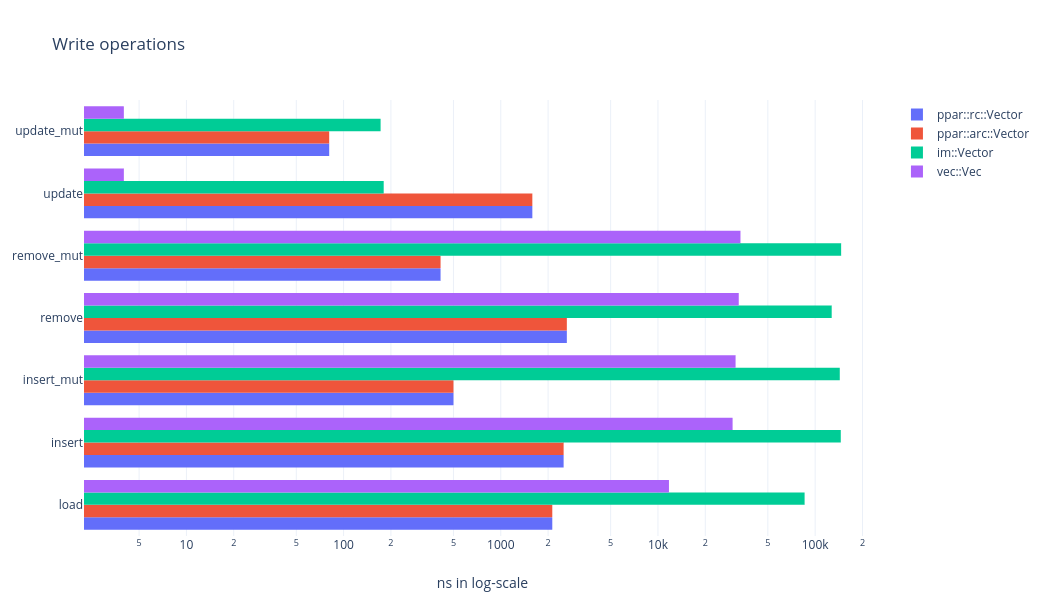 Lower number are better
Lower number are better
We are loading the array with an initial data set of 100_000 u64 numbers.
Then applying each operation in a tight loop, measuring the elapsed time
for the entire loop and finally computing per-op latency. insert,
insert_mut, remove, remove_mut, update, update_mut, and get use
random offset into the array. For iteration, we compute the elapsed time
for iterating each item.
- Using the logarithm scale implies an order-of-magniture difference in performance.
- Between
arcandrcvariant ofppar, performance difference is not much. Though it might make a difference for cache-optimized algorithms. ppargains order-of-magniture improvent overvecandimfor insert, remove, load, split, append, clone operations.- And it falls behind on update, get, iter operations. But it may be worth noting that where-ever it falls behind it is still on the lower end of the log-scale, that is, the difference is well within 100ns.
It is also worth noting that, maximum size of the operated data-set is less than 2MB, which means the entire array footprint can be held inside the CPU cache. As far as my understanding goes, when we increase the size of the array, the performance difference will only be more pronounced, that is, fast-op might look faster and slow-op might look slower.
Useful links
- im contains an alternate array implementation, among other things.
- rpds, another alternate implementation using
RRB-Tree. - rope datastructure used by this package.
Contributions
- Simple workflow. Fork - Modify - Pull request.
- Before creating a PR,
- Run
make buildto confirm all versions of build is passing with 0 warnings and 0 errors. - Run
check.shwith 0 warnings, 0 errors and all testcases passing. - Run
perf.shwith 0 warnings, 0 errors and all testcases passing. - Install and run
cargo spellcheckto remove common spelling mistakes.
- Run
- Developer certificate of origin is preferred.
Dependencies
~1.4–2.6MB
~57K SLoC