11 releases
| 0.9.3 | Oct 21, 2021 |
|---|---|
| 0.9.2 | Apr 2, 2021 |
| 0.9.1 | Mar 30, 2021 |
| 0.9.0 | Feb 20, 2021 |
| 0.6.1 | Jul 31, 2020 |
#116 in Programming languages
Used in passerine-aspen
240KB
4K
SLoC

The Passerine Programming Language
Made with ♡ by Isaac Clayton and the Passerine Community – a cornerstone of the Veritable Computation Initiative.
![]()
![]()
![]()
Why Passerine?
Passerine is a small, concise, extensible functional scripting language, powered by a VM† written in Rust. Here's a small taste:
Passerine has roots in Scheme and ML-flavored languages — it's the culmination of everything I expect from a programming language, including the desire to keep everything as minimalistic yet concise as possible. At its core, Passerine is lambda-calculus with pattern-matching, structural types, fiber-based concurrency, and syntactic extension.
† It's a bytecode VM with a few optimizations, so I'd say it's fast enough to be useful.
Who started this?
This is first project of The Veritable Computation Initiative. Our goal is to improve the tools developers use to write software. We're planning release a site with more information about Veritable soon.
Passerine is currently being developed by Isaac Clayton, a high-school student with too much free time on his hands. A few people have offered feedback and suggestions from time to time. Huge thanks to Raul, Hamza, Rishi, Lúcás, Anton, Yasser, Shaw†, Plecra, IFcoltransG, Jack, Keith‡, Xal, and others!
† Shaw is writing an alternative implementation of Passerine, and it's super fast. It's part of a wider effort of his to develop an efficient language-agnostic VM.
‡ Keith is currently sponsoring the development of Passerine — I'm deeply grateful for his support!
An Overview
Where this overview gets really exciting is when we dive into macros. If you're here to give Passerine a try, skip to Installation.
⚠️ Note that Passerine is a work in progress: features mentioned in this overview may not be implemented yet.
Syntax
The goal of Passerine's syntax is to make all expressions as concise as possible while still conserving the 'feel' of different types of expressions.
We'll start simple; here's a function that squares a number:
square = x -> x * x
square 4 -- is 16
By the way: Passerine uses
-- commentfor single-line comments and-{ comment }-for nestable multi-line comments.
There are already some important things we can learn about Passerine from this short example:
Like other programming languages, Passerine uses = for assignment. On the left hand side is a pattern – in this case, just the variable square – which destructures an expression into a set of bindings. On the right hand side is an expression; in this case the expression is a function definition.
Because Passerine is expression-oriented, the distinction between statements and expressions isn't made. In the case that an expression produces no useful value, it should return the Unit type,
(). Assignment, for instance, returns Unit.
The function call square 4 may look a bit alien to you; this is because Passerine uses whitespace for function calls. A function call takes the form l e₀ ... eₙ, where l is a function and e is an expression. square 4 is a simple case because square only takes one argument, x... let's try writing a function that takes two arguments!
Using our definition of square, here's a function that returns the Euclidean distance between two points:
distance = (x1, y1) (x2, y2) -> {
sqrt (square (x1 - x2) + square (y1 - y2))
}
origin = (0, 0)
distance origin (3, 4) -- is 5
Passerine is an expression-oriented language, because of this, it makes sense that all functions are anonymous. All functions take the form p₀ ... pₙ -> e, where p is a pattern and e is an expression. If a function takes multiple arguments, they can be written one after another; a b c -> d is equivalent to a -> (b -> (c -> d)).
The function distance is a bit more complex that square, because the two arguments are bound using tuple destructuring.
As you can see, distance takes two pairs, (x1, y1) and (x2, y2), and destructures each pair into its component parts. For instance, when we call distance in distance origin (3, 4) the function pulls out the numbers that make up the pair:
origin, i.e.(0, 0), is matched against(x1, y1), creating the bindingsx1 = 0andy1 = 0.- the tuple
(3, 4)is matched against(x2, y2), creating the bindingsx2 = 3andy2 = 4.
The body of distance, sqrt (...) is then evaluated in a new scope where the variables defined about are bound. In the case of the above example:
-- call and bind
distance origin (3, 4)
distance (0, 0) (3, 4)
-- substitute and evaluate
sqrt (square (0 - 3) + square (0 - 4))
sqrt (9 + 5)
sqrt 25
5
Now, you may have noticed that distance is actually two functions. It may be more obvious it we remove some syntactic sugar rewrite it like so:
distance = (x1, y1) -> { (x2, y2) -> { ... } }
The first function binds the first argument, then returns a new function that binds the second argument, which evaluates to a value. This is known as currying, and can be really useful when writing functional code.
To leverage currying, function calls are left-associative. The call
a b c dis equivalent to((a b) c) d, nota (b (c d)). This syntax comes from functional languages like Haskell and OCaml, and makes currying (partial application) quite intuitive.
In the above example, we used distance to measure how far away (3, 4) was from the origin. Coincidentally, this is known as the length of a vector. Wouldn't it be nice if we could define length in terms of distance?
length = distance origin
length (5, 12) -- is 13
Because distance is curried, we can call it with only one of its arguments. For this reason, length is a function that takes a pair and returns its distance from the origin. In essence, we can read the above definition of length as:
lengthis thedistancefromorigin.
Transforming data through the use of and functions and pattern matching is a central paradigm of Passerine. In the following sections, we'll dive deep and show how this small core language is enough to build a powerful and flexible language.
A Quick(-sort) Example
Here's another slightly more complex example – a recursive quick-sort with questionable pivot selection:
sort = list -> match list {
-- base case
[] -> []
-- pivot is head, tail is remaining
[pivot, ..tail] -> {
higher = filter { x -> x >= pivot } tail
lower = filter { x -> x < pivot } tail
(sorted_lower, sorted_higher) = (sort lower, sort higher)
sorted_lower
+ [pivot]
+ sorted_higher
}
}
The first thing that you should notice is the use of a match expression. Like ML-style languages, Passerine makes extensive use of pattern matching and destructuring as a driver of computation. A match expression takes the form:
match value {
pattern₀ -> expression₀
...
patternₙ -> expressionₙ
}
Each pattern -> expression pair is a branch – each value is against each branch in order until a branch successfully matches and evaluates – the match expression takes on the value of the matching branch. We'll take a deep dive into match statements later, so keep this in mind.
You might've also noticed the use of curly braces { ... } after [head, ..tail]. This is a block, a group of expressions executed one after another. Each expression in a block is separated by a newline or semicolon; the block takes on the value of its last expression.
The next thing to notice is this line:
(sorted_lower, sorted_higher) = (sort lower, sort higher)
This is a more complex assignment than the first one we saw. In this example, the pattern (sorted_lower, sorted_higher) is being matched against the expression (sort lower, sort higher). This pattern is a tuple destructuring, if you've ever used Python or Rust, I'm sure you're familiar with it. This assignment is equivalent to:
sorted_lower = sort lower
sorted_higher = sort higher
There's no real reason to use tuple destructuring here – idiomatically, just using sort lower and sort higher is the better solution. We discuss pattern matching in depth in the next section.
Passerine also supports higher order functions (this should come as no surprise):
filter { x -> x >= pivot } tail
filter takes a predicate (a function) and an iterable (like a list), and produces a new iterable where the predicate is true for all items. Although parenthesis could be used to group the inline function definition after filter, it's stylistically more coherent to use blocks for regions of computation. What's a region of computation? A region of computation is a series of multiple expressions, or a single expression that creates new bindings, like an assignment or a function definition.
Passerine also allows lines to be split around operators to break up long expressions:
sorted_lower
+ [pivot]
+ sorted_higher
Although this is not a particularly long expression, splitting up lines by operations can help improve the legibility of some expressions.
Function Application
Before we move on, here's a clever implementation of FizzBuzz in Passerine:
fizzbuzz = n -> {
test = d s x
-> if n % d == 0 {
_ -> s + x ""
} else { x }
fizz = test 3 "Fizz"
buzz = test 5 "Buzz"
"{n}" . fizz (buzz (i -> i))
}
1..100 . fizzbuzz . print
. is the function application operator:
-- the composition
a . b c . d
-- is left-associative
(a . (b c)) . d
-- and equivalent to
d ((b c) a)
Pattern Matching
In the last section, we touched on pattern matching a little. I hope to now go one step further and build a strong argument as to why pattern matching in Passerine is such a powerful construct. Patterns are used in in three places:
- Assignments,
- Functions,
- and Type Definitions.
We'll briefly discuss each type of pattern and the context in which they are used.
What are patterns?
Patterns extract data from types by mirroring the structure of those types. The act of applying a pattern to a type is called matching or destructuring – when a pattern matches some data successfully, a number of bindings are produced.
Passerine supports algebraic data types, and all of these types can be matched and destructured against. Here is a table of Passerine's patterns:
In the following table,
pis a nested sub-pattern.
| pattern | example | destructures |
|---|---|---|
| variable | foo |
Terminal pattern, binds an variable to a value. |
| data | 420.69 |
Terminal pattern, data that must match, raises an error otherwise. See the following section on fibers and concurrency to get an idea of how errors work in Passerine. |
| discard | _ |
Terminal pattern, matches any data, does not produce a binding. |
| label | Baz p |
Matches a label, i.e. a named type in Passerine. |
| tuple | (p₀, ...) |
Matches each element of a tuple, which is a group of elements, of potentially different types. Unit () is the empty tuple. |
| list | []/[p₀, ..p₁] |
[] Matches an empty list - p₀ matches the head of a list, ..p₁ matches the tail. |
| record | {f₀: p₀, ...} |
A record, i.e. a struct. This is a series of field-pattern pairs. If a field does not exist in the target record, an error is raised. |
| enum | {p₀; ...} |
An enumeration, i.e. a union. Matches if any of the patterns hold. |
| is | p₀: p₁ |
A type annotation. Matches against p₀ only if p₁ holds, errors otherwise. |
| where | p | e |
A bit different from the other patterns so far. Matches p only if the expression e is true. |
That's quite a lot of information, so let's work through it. The simplest case is a standard assignment:
a = b
-- produces the binding a = b
This is very straightforward and we've already covered this, so let's begin by discussing matching against data. The following function will return the second argument if the first argument passed to the function is true.
true second -> second
If the first argument is not true, say false, Passerine will yell at us:
Fatal Traceback, most recent call last:
In src/main.pn:1:1
|
1 | (true second -> second) false "Bananas!"
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
In src/main.pn:1:2
|
1 | (true second -> second) false "Bananas!"
| ^^^^
|
Runtime Pattern Matching Error: The data 'false' does not match the expected data 'true'
Discard is another simple pattern – it does nothing. It's most useful when used in conjunction with other patterns:
-- to ensure an fruit has the type Banana:
banana: Banana _ = mystery_fruit
-- to ignore an item in a tuple:
(_, plays_tennis, height_in_feet) = ("Juan Milan", true, 27.5)
-- to ignore a field on a record:
{ name: "Isaac Clayton", age: _, skill } = isaac
A label is a name given to a type. Of course, names do not imply type safety, but they do do a darn good job most of the time:
-- make a soft yellow banana:
banana = Banana ("yellow", "soft")
-- check that the banana flesh is soft:
if { Banana (_, flesh) = banana; flesh == "soft" } {
print "Delicioso!"
}
Pattern matching on labels is used to extract the raw data that is used to construct that label.
Tuples are fairly simple – we already covered them – so we'll cover records next. A record is a set of fields:
-- define the Person type
type Person {
name: String,
age: Natural,
skill, -- polymorphic over skill
}
-- Make a person. It's me!
isaac = Person {
name: "Isaac Clayton",
age: 16,
skill: Wizard "High enough ¯\_(ツ)_/¯",
}
Here's how you can pattern match on isaac:
Person {
-- aliasing field `name` as `full_name`
name: full_name,
-- `age` is ignored
age: _,
-- short for `skill: skill`
skill,
} = isaac
Of course, the pattern after the field is a full pattern, and can be matched against further.
Is is a type annotation:
Banana (color, _): Banana (_, "soft") = fruit
In this example, color will be bound if fruit is a Banana whose 1nd† tuple item is "soft".
† Read as 'firnd', corresponds to the 1-indexed second item. Zerost, firnd, secord, thirth, fourth, fifth...
Finally, we'll address my favorite pattern, where. Where allows for arbitrary code check the validity of a pattern. This can go a long way. For example, let's define natural numbers in terms of integers:
type Natural n: Integer | n >= 0
This should be interpreted as:
The type
Naturalis anIntegernwherenis greater than0.
With this definition in place:
-- this is valid
seven = Natural 7
-- this is not
negative_six = Natural -6
Where clauses in patterns ensure that the underlying data of a type can never break an invariant. As you can imagine, this is more powerful than ensuring name-safety through type constructors.
TODO: traits and impls.
Pattern matching and algebraic data types allow for quickly building up and tearing down expressive data schemas. As data (and the transformation applied to it) are the core of any program, constructs for quickly building up and tearing down complex datatypes are an incredible tool for scripting expressive applications.
Fibers
How does passerine handle errors? What about concurrency?
What do prime sieves, exceptions, and for-loops have in common? If you guessed concurrency, you won a bajillion points! Structured concurrency is a difficult problem to tackle, given how pervasive it is in the field language design.
It's important to point out that concurrency is not the same thing as parallelism. Concurrent systems may be parallel, but that's not always the case. Passerine subscribes to the coroutine model of structured concurrency – more succinctly, Passerine uses fibers – as exemplified by Wren. A fiber is a lightweight process of execution that is cooperatively scheduled with other fibers. Each fiber is like a little system unto itself that can pass messages to other fibers.
TODO: Algebraic Effects?
Error handling
Passerine uses a combination of exceptions and algebraic data types to handle errors. Errors that are expected to happen should be wrapped in a Result type:
validate_length = n -> {
if length n < 5 {
Result.Error "It's too short!"
} else {
Result.Ok n
}
}
Some errors, however, are unexpected. There are an uncountable number of ways software can fail; to account for all external circumstances is flat-out impossible in some cases.
For this reason, in the case that something that isn't expected to fail fails, an exception is raised. For example, trying to open a file that should exist may throw an error if it has been lost, moved, corrupted, or otherwise has incorrect permissions.
config = Config.parse (open "config.toml")
.is the indexing operator. On a list or tuple,items.0returns the zerost item; on a record,record.fieldreturns the specified field; on a label,Label.methodreturns the specified associated method.
The reason we don't always need to handle these errors is because Passerine follows a fail-fast, fail-safe philosophy. In this regard, Passerine subscribes to the philosophy of Erlang/Elixir:
"Keep calm and let it crash."
The good news is that crashes are local to the fiber they occur in – a single fiber crashing does not bring down the whole system. The idiomatic way to handle an operation that we know may fail is to try it. try performs the operation in a new fiber and converts any exceptions that may occur into a Result:
config = match try (open "config.toml") {
Result.Ok file -> Config.parse file
Result.Error error -> Config.default ()
}
We know that some functions may raise errors, but how can we signal that something exceptionally bad has happened? We use the error keyword!
doof = platypus -> {
if platypus == "Perry" {
-- crashes the current fiber
error "What!? Perry the platypus!?"
} else {
-- oh, it's just a platypus...
work_on_inator ()
}
}
-- oh no!
inator = doof "Perry"
Note that the value of raised errors can be any data. This allows for programmatic recovery from errors:
-- socket must not be disconnected
send_data = (
socket
data
) -> match socket.connection {
-- `Disconnected` is a labeled record
Option.None -> error Disconnected {
socket,
message: "Could not send data; disconnected",
}
-- if the connection is open, we send the data
Option.Some connection -> connection.write data
}
Let's say the above code tries to send some data through a socket. To handle a disconnection, we can try the error:
ping = socket -> try (send_data socket "ping")
socket = Socket.new "isaac@passerine.io:42069" -- whatever
socket.disconnect () -- oh no!
result = ping socket
match result {
Result.Ok "pong" -> ()
Result.Error Disconnected socket -> socked.connect
}
Why make the distinction between expected errors (Result) and unexpected errors (fiber crashes)? Programs only produce valid results if the environments they run in are valid. When a fiber crashes, it's signaling that something about the environment it's running in is not valid. This is very useful to developers during development, and very useful to programs in contexts where complex long-running applications may fail for any number of reasons.
Why not only use exceptions then? Because it's perfectly possible for an error to occur that is not exceptional at all. Malformed input, incorrect permissions, missing items – these are all things that can occur and do occur on a regular basis. It's always important to use the right tool for the job; prefer expected errors over unexpected errors.
Concurrency
Fibers are for more than just isolating the context of errors. As mentioned earlier:
A fiber is a lightweight process of execution that is cooperatively scheduled with other fibers. Each fiber is like a little system unto itself that can pass messages to other fibers.
Passerine leverages fibers to handle errors, but fibers are full coroutines. To create a fiber, use the fiber keyword:
counter = fiber {
i = 0
loop { yield i; i = i + 1 }
}
print counter () -> prints 0
print counter () -> prints 1
print counter () -> ...
The yield keyword suspends the current fiber and returns a value to the calling fiber. yield can also be used to pass data into a fiber.
passing_yield = fiber {
print "hello"
result = yield "banana"
print result
"yes"
}
passing_yield "first" -- prints "hello" then evaluates to "banana"
passing_yield "second" -- prints "second" then evaluates to "yes"
passing_yield "uh oh" -- raises an error, fiber is done
To build more complex systems, you can build fibers with functions:
-- a function that returns a fiber
flopper = this that -> fiber {
loop {
yield this
yield that
}
}
apple_banana = flopper "Apple" "Banana"
apple_banana () -- evaluates to "Apple"
apple_banana () -- evaluates to "Banana"
apple_banana () -- evaluates to "Apple"
apple_banana () -- ... you get the point
Of course, the possibilities are endless. There's one last thing I'd like to discuss before we start talking about macros. Fibers, while usually being ran in the context of another, all act as peers to each-other. If you have a reference to a fiber, it's possible to transfer to it forgetting the context in which it was called. To switch to a fiber, use switch.
banana_and_end = fiber {
print "banana ending!"
}
print "the beginning..."
switch banana_and_end
print "the end."
"the end." is never displayed.
'Tis not the end, 'tis but the beginning... 'tis hackin' time!
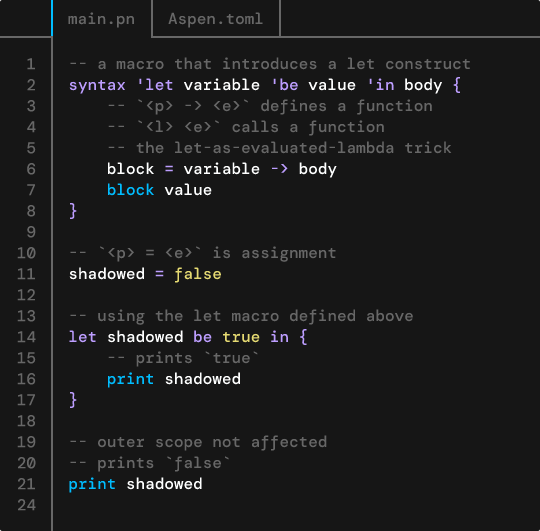
Macros
Passerine has a rich hygienic* syntactic macro system that extends the language itself.
Syntactic macros, quite simply, are bits of code that hygienically produce more code when invoked at compile time. Macros use a small, simple-yet-powerful set of rules to transform code.
* Having read Doug Hoyte's exellent Let Over Lambda, I understand the raw power of a rich unhygenic macro system. However, such systems are hard to comprehend, and harder to master. Passerine aims to be as simple and powerful as possible without losing transparency: hygienic macro systems are much more transparent then their opaque unhygenic counterparts.
Hygiene
Extensions are defined with the syntax keyword, followed by some argument patterns, followed by the code that the captured arguments will be spliced into. Here's a simple example: we're using a macro to define swap operator:
syntax a 'swap b {
tmp = a
a = b
b = tmp
}
x = 7
y = 3
x swap y
Note that the above code is completely hygienic. the expanded macro looks something like this:
_tmp = x
x = y
x = _tmp
Because tmp was not passed as a macro pattern parameter, all uses of tmp in the macro body are unique unrepresentable variables that do not collide with any other variables currently bound in scope. Essentially:
tmp = 1
x = 2
y = 3
x swap y
Will not affect the value of tmp; tmp will still be 1.
Argument Patterns
So, what is an argument pattern (an arg-pat)? Arg-pats are what go between:
syntax ... { }
Each item between syntax and the macro body is an arg-pat. Arg-pats can be:
- Syntactic variables, like
fooandbar. - Literal syntactic identifiers, which are prefixed with a quote (
'), like'let. - Nested argument patterns, followed by optional modifiers.
Let's start with syntactic identifiers. Identifiers are literal names that must be present for the pattern to match. Each syntactic extension is required to have at least one. For example, here's a macro that matches a for loop:
syntax 'for binding 'in values do { ... }
In this case, 'for and 'in are syntactic identifiers. This definition could be used as follows:
for a in [1, 2, 3] {
print a
}
Syntactic variables are the other identifiers in the pattern that are bound to actual values. In the above example, a → binding, [1, 2, 3] → values, and { print a } → do.
Macros can also be used to define operators†:
syntax sequence 'contains value {
c = seq -> match seq {
[] -> False
[head, ..] | head == value -> True
[_, ..tail] -> c tail
}
c sequence
}
This defines a contains operator that could be used as follows:
print {
if [1, 2, 3] contains 2 {
"It contains 2"
} else {
"It does not contain 2"
}
}
Evidently, It contains 2 would be printed.
† Custom operators defined in this manner will always have the lowest precedence, and must be explicitly grouped when ambiguous. For this reason, Passerine already has a number of built-in operators (with proper precedence) which can be overloaded. It's important to note that macros serve to introduce new constructs that just happen to be composable – syntactic macros can be used to make custom operators, but they can be used for so much more. I think this is a fair trade-off to make.
Modifiers are postfix symbols that allow for flexibility within argument patterns. Here are some modifiers:
- Zero or more (
...) - Optional (
?)
Additionally, parenthesis are used for grouping, and { ... } are used to match expressions within blocks. Let's construct some syntactic arguments that match an if else statement, like this one:
if x == 0 {
print "Zero"
} else if x % 2 == 0 {
print "Even"
} else {
print "Not even or zero"
}
The arg-pat must match a beginning if:
syntax 'if { ... }
Then, a condition:
syntax 'if condition { ... }
Then, the first block:
syntax 'if condition then { ... }
Next, we'll need a number of else if <condition> statements:
syntax 'if condition then ('else 'if others do)... { ... }
Followed by a required closing else (Passerine is expression oriented and type-checked, so a closing else ensures that an if expression always returns a value.):
syntax 'if condition then ('else 'if others do)... 'else finally { ... }
Of course, if statements are already baked into the language – let's build something else – a match expression.
Building a match expression
A match expression takes a value and a number of functions, and tries to apply the value to each function until one successfully matches and runs. A match expression looks as like this:
l = Some (1, 2, 3)
match l {
Some (m, x, b) -> m * x + b
None -> 0
}
Here's how we can match a match expression:
syntax 'match value { arms... } {
-- TODO: implement the body
}
This should be read as:
The syntax for a match expression starts with the pseudokeyword
match, followed by thevalueto match against, followed by a block where each item in the block gets collected into the listarms.
What about the body? Well:
- If no branches are matched, an error is raised.
- If are some branches, we
trythe first branch in a new fiber and see if it matches. - If the function doesn't raise a match error, we found a match!
- If the function does raise a match error, we try again with the remaining branches.
Let's start by implementing this as a function:
-- takes a value to match against
-- and a list of functions, branches
match_function = value branches -> {
if branches.is_empty {
error Match "No branches matched in match expression"
}
result = try { (head branches) value }
if result is Result.Ok _ {
Result.Ok v = result; v
} else if result is Result.Error Match _ {
match_function value (tail branches)
} else if result is Result.Error _ {
-- a different error occurred, so we re-raise it
Result.Error e = result; error e
}
}
I know the use of if to handle tasks that pattern matching excels at hurts a little, but remember, that's why we're building a match expression! Using base constructs to create higher-level affordances with little overhead is a core theme of Passerine development.
Here's how you could use match_function, by the way:
-- Note that we're passing a list of functions
description = match_function Banana ("yellow", "soft") [
Banana ("brown", "mushy") -> "That's not my banana!",
Banana ("yellow", flesh)
| flesh != "soft"
-> "I mean it's yellow, but not soft",
Banana (peel, "soft")
| peel != "yellow"
-> "I mean it's soft, but not yellow",
Banana ("yellow", "soft") -> "That's my banana!",
Banana (color, texture)
-> "Hmm. I've never seen a { texture } { color } banana before...",
]
This is already orders of magnitude better, but passing a list of functions still feels a bit... hacky. Let's use our match macro definition from earlier to make this more ergonomic:
syntax 'match value { arms... } {
match_function value arms
}
We've added match expression to Passerine, and they already feel like language features*! Isn't that incredible? Here's the above example we used with match_function adapted to match†:
description = match Banana ("yellow", "soft") {
Banana ("brown", "mushy") -> "That's not my banana!"
Banana ("yellow", flesh)
| flesh != "soft"
-> "I mean it's yellow, but not soft"
Banana (peel, "soft")
| peel != "yellow"
-> "I mean it's soft, but not yellow"
Banana ("yellow", "soft") -> "That's my banana!"
Banana (color, texture)
-> "Hmm. I've never seen a { texture } { color } banana before..."
}
† Plot twist: we just defined the
matchexpression we've been using throughout this entire overview.
Modules
Passerine's module system allows large codebases to be broken out into indiviual reusable components. A module is a scopes turned into a struct, and isn't necessarily tied to the file system.
Modules are defined using the mod keyword, which must be followed by a block { ... }. Here's a simple module that defines some math utilities:
circle = mod {
PI = 3.14159265358979
area = r -> r * PI * PI
circum = r -> r * PI * 2
}
pizza_radius = 12
slices = 8
slice_area = (circle::area pizza_radius) / slices
mod takes all top-level declarations in a block - in this case, PI, area, and circum - and turns them into a struct with those fields. In essence, the above is equivalent to this struct:
circle = {
PI: 3.14159265358979
area: r -> r * PI * PI
circum: r -> r * PI * 2
}
mod is nice because it's an easy way to have multiple returns. In essesence, the mod keyword allows for first-class scoping, by turning scopes into structs:
index = numbers pos
-> floor (len numbers * pos)
quartiles = numbers -> mod {
sorted = (sort numbers)
med = sorted::(index (1/2) sorted)
q1 = sorted::(index (1/4) sorted)
q3 = sorted::(index (3/4) sorted)
}
Because we used the mod keyword in the above example, instead of returning a single value from the function, we return a struct containing all values in the fuction:
-- calculate statistics
numbers = [1, 2, 3, 4, 5]
stats = quartiles numbers
-- use `q1` and `q3` to calculate the interquartile range of `numbers`
iqr = stats::q3 - stats::q1
print "the IQR of { numbers } is { iqr } "
This is really useful for writing functions that return multiple values.
Aside from allowing us to group sets of related values into a single namespace, modules can be defined in different files, then be imported. Here's a module defined in a different file:
-- list_util.pn
reduce = f start list -> match list {
[] -> start,
[head, ..tail] -> f (reduce f tail, head)
}
sum = reduce { (a, b) -> a + b } 0
reverse = reduce { (a, b) -> [b.., a]} []
This file defines a number of useful list utilities, defined in a traditional recursive style. If we want to use this module in main.pn, we import it using the use keyword:
-- main.pn
use list_util
numbers = [1, 1, 2, 3, 5]
print (list_util::sum numbers)
Note that the use keyword is essentially the same thing as wrapping the contents of the imported file with the mod keyword:
-- use list_util
list_util = mod { <list_util.pn> }
Once imported, list_util is just a struct. Because of this, features of the module system naturally arise from Passerine's existing semantics for manipulating structs. To import a subset of a module, we can do something like this:
reverse = { use list_util; list_util::reduce }
Likewise, we can import a module within a block scope to rename it:
list_stuff = { use list_util; list_util }
There are a number of nice properties that arise from this module system, we've just scratched the surface. As modules are just structs, the full power of passerine and its macro system are at your disposal for building extensible systems that compose well.
Concluding Thoughts
Thanks for reading this far. Passerine has been a joy for me to work on, and I hope you find it a joy to use.
A few of the features discussed in this overview haven't been implemented yet. We're not trying to sell you short, it's just that developing a programming language and bootstrapping a community around it at the same time is not exactly easy. If you'd like something added to Passerine, open an issue or pull request, or check out the roadmap.
FAQ
Q: Is Passerine ready for production use?
A: Not yet. Passerine is still in early stages of development, with frequent breaking changes. See the project roadmap (down below 👇) to get an idea of what's in development.
Q: Is Passerine statically typed?
A: so currently Passerine is strongly and dynamically¹ typed (technically structurally typed). This is partially out of necessity – Types are defined by patterns, and patterns can be where predicated. However, I've been doing a lot of research into Hindley-Milder type systems, and the various extensions that can be applied to them.
I'm working towards making a compile-time type-checker for the language, based on Hindley-Milner type inference. With this system in place, I can make some assumptions to speed up the interpreter further and perhaps monomorphize/generate LLVM IR / WASM.
This type checker is actually the target of the next release, so stay tuned!
Q: What about algebraic effects and kind-based macros?
A: I'm interested in eventually adding both these things to the language, but first I need to implement a nice type-checker and do some more research. Algebraic Effects would fill the design space of fibers, and kind based macros would provide a more solid base for passerine's macro system. Got any fresh language features you think would complement Passerine's design philosophy? Reach out!
Q: What is vaporization memory management?
A: When I was first designing Passerine, I was big into automatic compile-time memory management. Currently, there are a few ways to do this: from Rust's borrow-checker, to µ-Mitten's Proust ASAP, to Koka's Perceus, there are a lot of new and exciting ways to approach this problem.
Vaporization is an automatic memory management system that allows for Functional but in Place style programming. For vaporization to work, three invariants must hold:
- All functions params are passed by value via a copy-on-write reference. This means that only the lifetimes of the returned objects need to be preserved, all others will be deleted when they go out of scope.
- A form of SSA is performed, where the last usage of any value is not a copy of that value.
- All closure references are immutable copies of a value. These copies may be reference-counted in an acyclical manner.
With these invariants in place, vaporization ensures two things:
- Values are only alive where they are still useful.
- Code may be written in a functional style, but all mutations occur in-place as per rule 2.
What's most interesting is that this system requires minimal interference from the compiler when used in conjunction with a VM. All the compiler has to do is annotate the last usage of the value of any variables; the rest can be done automatically and very efficiently at runtime.
Why not use this? Mainly because of rule 3: 'closure references are immutable'. Passerine is pass-by-value, but currently allows mutation in the current scope a la let-style redefinition. But this is subject to change; and once it does, it's vaporization all the way, baby!
Q: Aren't there already enough programming languages?
A: Frankly, I think we've barely scratched the surface of programming language design. To say that Programming Language Design is saturated and at a local maxima is to not understand the nature of software development. Passerine is largely a test as to whether I can build a modern compiler pipeline. But what I'm even more interested in is the tooling that surrounds development environments.
Case in point: text-based entry for programming languages has been around forever because it's fast. However, it's not always semantically correct. The number of correct programs is an infinity smaller than the number of possible text files. Yet it's still possible to make text-based entry systems that ensure semantic correctness while encouraging exploration. In the future, we need to develop new tools that more closely blur the line between language and environment. Pharo is a step in the right direction, as are Unison and similar efforts.
I'd like to focus more on this in the future. An interesting project would be an editor/environment like Pharo/Unison for a small minimal language, like Scheme, or perhaps even Passerine.
Installation
Passerine is still very much so a work in progress. We've done a lot, but there's still a so much more to do!
For you pioneers out there, The best way to get a feel for Passerine is to install Aspen¹, Passerine's package manager and CLI.
If you use a *nix-style² system, run³:
sh <(curl -sSf https://www.passerine.io/install.sh)
- If you're having trouble getting started, reach out on the community Discord server.
- Tested on Arch (btw) and macOS.
- Now tested on Windows™!
- (Also, experimentally supports Wasm.)
- In the future, we plan to distribute prebuilt binaries, but for now, both Git and Cargo are required.
Contributing
Contributions are welcome! Read our Contribution Guide and join the Discord server to get started!
If you'd like to contribute to the project but don't have much time to spare, consider donating. Thank you!
Roadmap
See the Project Roadmap to get a feel for what's currently under development.