2 releases
| 0.1.1 | Nov 15, 2024 |
|---|---|
| 0.1.0 | Nov 11, 2024 |
#1408 in Parser implementations
38KB
166 lines
Html simple parser
This is an implementation of a basic html parser written in Rust using Pest. This tool reads an HTML file, validates its structure, and provides a nested, hierarchical representation of the HTML elements within it.
Links
https://crates.io/crates/html_simple_parser
https://docs.rs/html_simple_parser/0.1.0/html_simple_parser/
Overview
This html parser is designed to determine the correctness of the html structure and information about the HTML elements, their nesting, and the relationships between them. It is particularly useful for getting Html Dom in a convenient format for the user with a hierarchy of tags.
Features
This parser can process:
- Basic HTML tags.
- Text elements that appear between HTML tags.
More other features:
- Detecting html errors, such as invalid html structure error and tag names mismatch error.
- Outputs a structured, indented tree view of HTML elements, helping users understand the layout of the document.
Technical description of the parsing process
Tokenizer
At the first stage, after receiving the file from the user, the internal html code is removed from it. Then it is processed with grammatical rules using the pest library. All rules are defined in the grammar.pest file. They define the general structure of the file, including tags, text data, and documentation.
Syntax Analysis
At the stage of parsing, each element of the html structure is processed according to a grammatical rule. If an element does not fit any of the rules, an error is thrown about the mismatch of the html structure - ErrorHtmlStructure. Also, during the parsing process, the correspondence of the closing and opening tags is checked, if the tag names do not match, an error will be thrown - MismatchedClosingTag.
Сreating a tree-like html structure
The parser builds a nested tree structure from HTML tokens that represents a hierarchy of elements. Each node in the tree corresponds to an HTML element (such as html, head, body, etc.) containing information about the tag name and its child nodes.
Showing the result
The resulting tree structure can then be displayed in a command-line view, where each level of indentation represents the nesting level of HTML elements.
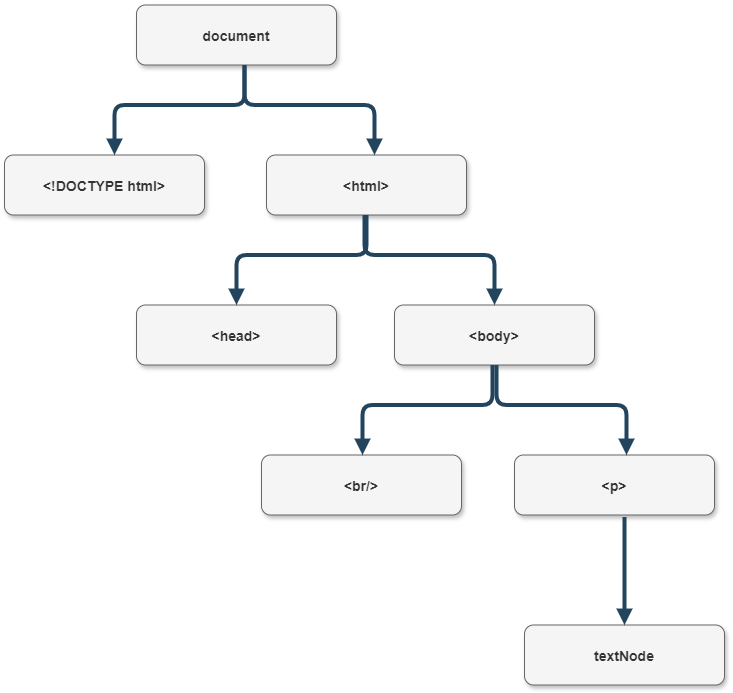
Tree Diagram
For a better understanding of the output tree, for example, this html code:
<!DOCTYPE html>
<html>
<head></head>
<body>
<br/>
<p>Some text</p>
</body>
</html>
will have the following output tree:
Grammar Rules
document = {SOI ~ WHITESPACE* ~ declaration? ~ WHITESPACE* ~ (elem | self_closed_tag)* ~ WHITESPACE* ~ EOI}
The root rule that specifies an HTML document must begin with a doctype and contain an tag element.
declaration = {"<!DOCTYPE html>"}
Defines the required HTML doctype declaration.
elem = {start_tag ~ WHITESPACE* ~ (elem | text | self_closed_tag)* ~ WHITESPACE* ~ end_tag}
Defines a general HTML tag with a start and end tag and children such as other tags and text.
start_tag = { "<" ~ tag_name ~ ">" }
The initial tag that opens the tag block.
end_tag = { "</" ~ tag_name ~ ">" }
Сlosing tag that follows the opening tag and all nested elements.
self_closed_tag = { "<" ~ tag_name ~ "/>"}
Defines self-closing tags like br or img.
tag_name = @{ ASCII_ALPHA+ }
A sequence of alphanumeric characters representing a tag's name.
text = {(!"<" ~ ANY)+}
Captures text content inside tags.
Example Output
Given input:
<!DOCTYPE html>
<html>
<head>
</head>
<body>
<h1>Hello, world!</h1>
</body>
</html>
The output will be:
<!DOCTYPE html>
html
head
body
h1
(Hello, world!)
Usage
Display Help
To view the help message with usage information:
cargo run -- --help
make help
Parse an HTML File
To parse a specific HTML file and print its structure:
cargo run -- parse path/to/file.html
make run FILE=path/to/file.html
Display Credits
To see the credits:
cargo run -- credits
make credits
Dependencies
~4MB
~74K SLoC