2 releases
Uses old Rust 2015
| 0.1.1 | Aug 27, 2016 |
|---|---|
| 0.1.0 | Aug 27, 2016 |
#2217 in Algorithms
1,414 downloads per month
Used in 3 crates
31KB
320 lines
Eudex: A blazingly fast phonetic reduction/hashing algorithm.
Eudex ([juːˈdɛks]) is a Soundex-esque phonetic reduction/hashing algorithm, providing locality sensitive "hashes" of words, based on the spelling and pronunciation.
It is derived from the classification of the pulmonic consonants (see below).
Eudex is about two orders of magnitude faster than Soundex, and several orders of magnitude faster than Levenshtein distance, making it feasible to run on large sets of strings in very short time.
Features
- High quality locality-sensitive hashing based on pronunciation.
- Works with, but not limited to, English, Catalan, German, Spanish, Italian, and Swedish.
- Sophisticated phonetic mapping.
- Better quality than Soundex.
- Takes non-english letters into account.
- Extremely fast.
- Algorithm specified (see the section below).
- Vowel sensitive.
FAQ
Why aren't Rupert and Robert mapped to the same value, like in Soundex? Eudex is not a phonetic classifier, it is a phonetic hasher. It maps words in a manner that exposes the difference. Soundex doesn't give any form of nuanced measure, only "Similar" and "Not similar".
The results seems completely random. What is wrong? It is likely because
you assume that the hashes of similar sounding words are mapped near to each
other, while they don't. Instead, their Hamming distance (i.e. XOR the values
and sum their bits) will be low. distance now accounts for this.
I am concerned about stability. Can the values vary?. Yes! You are
encouraged to either specify the revision to Cargo, giving you complete
stability, or use the similar function, whose fundamental behavior won't
change.
Does it support non-English letters? Yes, it supports all the C1 letters (e.g., ü, ö, æ, ß, é and so on), and it takes their respective sound into account.
Is it English-only? No, it works on most European languages as well. However, it is limited to the Latin alphabet.
How does it work? It is described below.
Does it take digraphs into account? The table is designed to encapsulate digraphs as well, though there is no separate table for these (like in Metaphone).
Does it replace Levenshtein? It is not a replacement for Levenshtein distance, it is a replacement for Levenshtein distance in certain use cases, e.g. searching for spell check suggestions.
What languages is it tested for? It is tested on the English, Catalan, German, Spanish, Swedish, and Italian dictionaries, and has been confirmed to have decent to good quality on all of them.
It seem to limited the hash to 8 or 16 characters? It doesn't have such a limitation, however the hash will only be affected by the first N characters, due to platform and performance considerations. It turns out that it has little to no effect on the quality. Moreover, this limitation is not a part of the algorithm itself, but this implementation of the algorithm.
Implementations
- Rust: this repository.
- Java: jprante/elasticsearch-analysis-phonetic-eudex
- JavaScript: Yomguithereal/talisman
Example
extern crate eudex;
use eudex::Hash;
fn main() {
assert!((Hash::new("jumpo") - Hash::new("jumbo")).similar());
assert!(!(Hash::new("Horse") - Hash::new("Norse")).similar());
println!("{:?}", Hash::new("hello"));
}
Cargo
Add this to your Cargo.toml:
[dependencies.eudex]
git = "https://github.com/ticki/eudex.git"
The dark magic behind Eudex
The algorithm itself is fairly simple. It outputs an 8 byte array (an unsigned 64 bit integer):
A00BBBBB
||/\___/
|| |
|| Trailing phones
||
|Padding
|
First phone
The crucial point here is that all the characters are mapped through a table carefully derived by their phonetic classification, to make similar sounding phones have a low Hamming distance.
If two consecutive phones shares all the bits, but the parity bit, (i.e, a >> 1 = b >> 1), the second is skipped.
The tables are what makes it interesting. There are four tables: one for ASCII letters (not characters, letters) in the first slot ('A'), one for C1 (Latin Supplement) characters in the first slot, one for ASCII letters in the trailing phones, and one for the C1 (Latin Supplement) characters for the trailing phones.
There is a crucial distinction between consonants and vowels in Eudex. The first phone treat vowels as first-class citizens by making distinctions between all the properties of vowels. The trailing phones only have a distinction between open and close vowels.
Let's start with the tables for the trailing characters. Consonants' bytes are treated such that each bit represent a property of the phone (i.e., pronunciation) with the exception of the rightmost bit, which is used for tagging duplicates (it acts as a discriminant).
Let's look at the classification of IPA consonants:

As you may notice, characters often represent more than one phone, and reasoning about which one a given character in a given context represents can be very hard. So we have to do our best in fitting each character into the right phonetic category.
We have to pick the classification intelligently. There are certain groups the
table doesn't contain, one of which turns out to be handy in a classification:
liquid consonants (lateral consonants + rhotics), namely r and l. Under
ideal conditions, these should be put into to distinct bits, but unfortunately
there are only 8 bits in a byte, so we have to limit ourselves.
Now, every good phonetic hasher should be able to segregate important characters (e.g., hard to mispell, crucial to the pronunciation of the word) from the rest. Therefore we add a category we call "confident", this will occupy the most significant bit. In our category of "confident" characters we put l, r, x, z, and q, since these are either:
- Crucial to the sound of the word (and thus easier to hear, and harder to misspell).
- Rare to occur, and thus statistically harder to mistake.
So our final trailing consonant table looks like:
| Position | Modifier | Property | Phones |
|---|---|---|---|
| 1 | 1 | Discriminant | (for tagging duplicates) |
| 2 | 2 | Nasal | mn |
| 3 | 4 | Fricative | fvsjxzhct |
| 4 | 8 | Plosive | pbtdcgqk |
| 5 | 16 | Dental | tdnzs |
| 6 | 32 | Liquid | lr |
| 7 | 64 | Labial | bfpv |
| 8 | 128 | Confident¹ | lrxzq |
The more "important" the characteristic is to the phone's sound the higher place it has.
We then have to treat the vowels. In particular, we don't care much of vowels in trailing position, so we will simply divide them into two categories: open and close. It is worth noting that not all vowels fall into these categories, therefore we will simply place it in the category it is "nearest to", e.g. a, (e), o gets 0 for "open".
So our final ASCII letter table for the trailing phones looks like:
(for consonants)
+--------- Confident
|+-------- Labial
||+------- Liquid
|||+------ Dental
||||+----- Plosive
|||||+---- Fricative
||||||+--- Nasal
|||||||+-- Discriminant
||||||||
a* 00000000
b 01001000
c 00001100
d 00011000
e* 00000001
f 01000100
g 00001000
h 00000100
i* 00000001
j 00000101
k 00001001
l 10100000
m 00000010
n 00010010
o* 00000000
p 01001001
q 10101000
r 10100001
s 00010100
t 00011101
u* 00000001
v 01000101
w 00000000
x 10000100
y* 00000001
z 10010100
| (for vowels)
+-- Close
Now, we extend our table to C1 characters by the same method:
(for consonants)
+--------- Confident
|+-------- Labial
||+------- Liquid
|||+------ Dental
||||+----- Plosive
|||||+---- Fricative
||||||+--- Nasal
|||||||+-- Discriminant
||||||||
ß -----s-1 (use 's' from the table above with the last bit flipped)
à 00000000
á 00000000
â 00000000
ã 00000000
ä 00000000 [æ]
å 00000001 [oː]
æ 00000000 [æ]
ç -----z-1 [t͡ʃ]
è 00000001
é 00000001
ê 00000001
ë 00000001
ì 00000001
í 00000001
î 00000001
ï 00000001
ð 00010101 [ð̠] (represented as a non-plosive T)
ñ 00010111 [nj] (represented as a combination of n and j)
ò 00000000
ó 00000000
ô 00000000
õ 00000000
ö 00000001 [ø]
÷ 11111111 (placeholder)
ø 00000001 [ø]
ù 00000001
ú 00000001
û 00000001
ü 00000001
ý 00000001
þ -----ð-- [ð̠] (represented as a non-plosive T)
ÿ 00000001
| (for vowels)
+-- Close
So far we have considered the trailing phones, now we need to look into the first phone. The first phone needs a table with minimal collisions, since you hardly ever misspell the first letter in the word. Ideally, the table should be injective, but due to technical limitations it is not possible.
We will use the first bit to distinguish between vowels and consonants.
Previously we have only divided vowels into to classes, we will change that now, but first: the consonants. To avoid repeating ourselves, we will use a method for reusing the above tables.
Since the least important property is placed to the left, we will simply shift it to the right (that is, truncating the rightmost bit). The least significant bit will then be flipped when encountering a duplicate. This way we preserve the low Hamming distance, while avoiding collisions.
The vowels are more interesting. We need a way to distinguish between vowels and their sounds.
Luckily, their classification is quite simple:
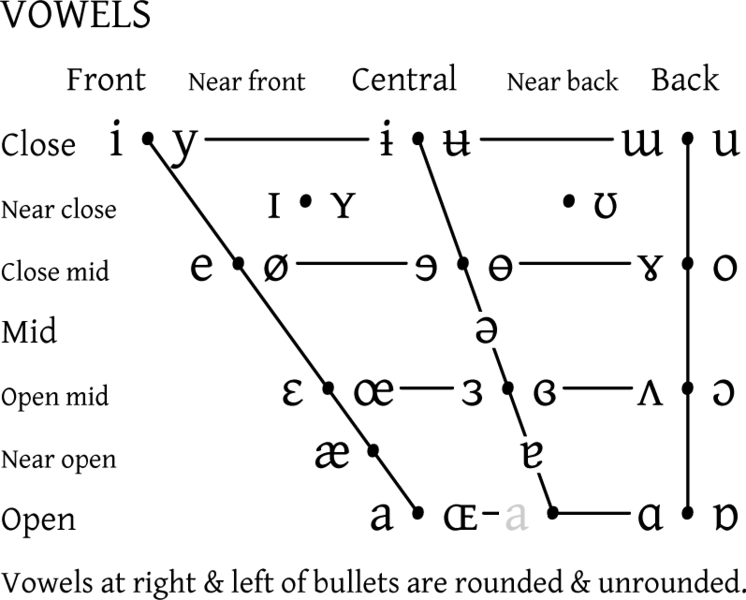
If a vowel appears as two phones (e.g., dependent on language), we OR them, and possibly modify the discriminant if it collides with another phone.
We need to divide each of the axises into more than two categories, to utilize all our bits, so some properties will have to occupy multiple bits.
| Position | Modifier | Property (vowel) |
|---|---|---|
| 1 | 1 | Discriminant |
| 2 | 2 | Is it open-mid? |
| 3 | 4 | Is it central? |
| 4 | 8 | Is it close-mid? |
| 5 | 16 | Is it front? |
| 6 | 32 | Is it close? |
| 7 | 64 | More close than [ɜ] |
| 8 | 128 | Vowel? |
So we make use of both properties, namely both the openness and "frontness". Moreover, we allow more than just binary choices:
Class Close Close-mid Open-mid Open
+----------+----------+-----------+---------+
Bits .11..... ...11... ......1. .00.0.0.
Let's do the same for the other axis:
Class Front Central Back
+----------+----------+----------+
Bits ...1.0.. ...0.1.. ...0.0..
To combine the properties we OR these tables. Applying this technique, we get:
(for vowels)
+--------- Vowel
|+-------- Closer than ɜ
||+------- Close
|||+------ Front
||||+----- Close-mid
|||||+---- Central
||||||+--- Open-mid
|||||||+-- Discriminant
||||||||
a* 10000100
b 00100100
c 00000110
d 00001100
e* 11011000
f 00100010
g 00000100
h 00000010
i* 11111000
j 00000011
k 00000101
l 01010000
m 00000001
n 00001001
o* 10010100
p 00100101
q 01010100
r 01010001
s 00001010
t 00001110
u* 11100000
v 00100011
w 00000000
x 01000010
y* 11100100
z 01001010
We then extend it to C1 characters:
+--------- Vowel?
|+-------- Closer than ɜ
||+------- Close
|||+------ Front
||||+----- Close-mid
|||||+---- Central
||||||+--- Open-mid
|||||||+-- Discriminant
||||||||
ß -----s-1 (use 's' from the table above with the last bit flipped)
à -----a-1
á -----a-1
â 10000000
ã 10000110
ä 10100110 [æ]
å 11000010 [oː]
æ 10100111 [æ]
ç 01010100 [t͡ʃ]
è -----e-1
é -----e-1
ê -----e-1
ë 11000110
ì -----i-1
í -----i-1
î -----i-1
ï -----i-1
ð 00001011 [ð̠] (represented as a non-plosive T)
ñ 00001011 [nj] (represented as a combination of n and j)
ò -----o-1
ó -----o-1
ô -----o-1
õ -----o-1
ö 11011100 [ø]
÷ 11111111 (placeholder)
ø 11011101 [ø]
ù -----u-1
ú -----u-1
û -----u-1
ü -----y-1
ý -----y-1
þ -----ð-- [ð̠] (represented as a non-plosive T)
ÿ -----y-1
Now that we have our tables. We now need the distance operator. A naïve approach would be to simply use Hamming distance. This has the disadvantage of all the bytes having the same weight, which isn't ideal, since you are more likely to misspell later characters, than the first ones.
For this reason, we use weighted Hamming distance:
| Byte: | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| Weight: | 128 | 64 | 32 | 16 | 8 | 4 | 2 | 1 |
Namely, we XOR the two values and then add each of the bytes' Hamming weight, using the coefficients from the table above.
This gives us a high quality word metric.