5 releases
| 0.5.5 | Mar 25, 2025 |
|---|---|
| 0.5.4 |
|
| 0.5.1 | Jan 9, 2025 |
| 0.4.18 |
|
| 0.1.23 |
|
#70 in Machine learning
331 downloads per month
480KB
11K
SLoC

![]()
![]()
![]()
Inference, Ingestion, and Indexing in Rust 🦀
Python docs »
Rust docs »
Benchmarks
·
FAQ
·
Adapters
.
Collaborations
EmbedAnything is a minimalist, highly performant, lightning-fast, lightweight, multisource, multimodal, and local embedding pipeline built in Rust. Whether you're working with text, images, audio, PDFs, websites, or other media, EmbedAnything streamlines the process of generating embeddings from various sources and seamlessly streaming (memory-efficient-indexing) them to a vector database. It supports dense, sparse, ONNX and late-interaction embeddings, offering flexibility for a wide range of use cases.
Table of Contents
🚀 Key Features
- Candle Backend : Supports BERT, Jina, ColPali, Splade, ModernBERT
- ONNX Backend: Supports BERT, Jina, ColPali, ColBERT Splade, Reranker, ModernBERT
- Cloud Embedding Models:: Supports OpenAI and Cohere.
- MultiModality : Works with text sources like PDFs, txt, md, Images JPG and Audio, .WAV
- Rust : All the file processing is done in rust for speed and efficiency
- GPU support : We have taken care of hardware acceleration on GPU as well.
- Python Interface: Packaged as a Python library for seamless integration into your existing projects.
- Vector Streaming: Continuously create and stream embeddings if you have low resource.
💡What is Vector Streaming
Vector Streaming enables you to process and generate embeddings for files and stream them, so if you have 10 GB of file, it can continuously generate embeddings Chunk by Chunk, that you can segment semantically, and store them in the vector database of your choice, Thus it eliminates bulk embeddings storage on RAM at once. The embedding process happens separetly from the main process, so as to maintain high performance enabled by rust MPSC. Find our blog.

🦀 Why Embed Anything
➡️Faster execution.
➡️Memory Management: Rust enforces memory management simultaneously, preventing memory leaks and crashes that can plague other languages
➡️True multithreading
➡️Running embedding models locally and efficiently
➡️Candle allows inferences on CUDA-enabled GPUs right out of the box.
➡️Decrease the memory usage of EmbedAnything.
➡️Supports range of models, Dense, Sparse, Late-interaction, ReRanker, ModernBert.
🍓 Our Past Collaborations:
We have collaborated with reputed enterprise like Elastic, Weaviate, SingleStore and Datahours
You can get in touch with us for further collaborations.
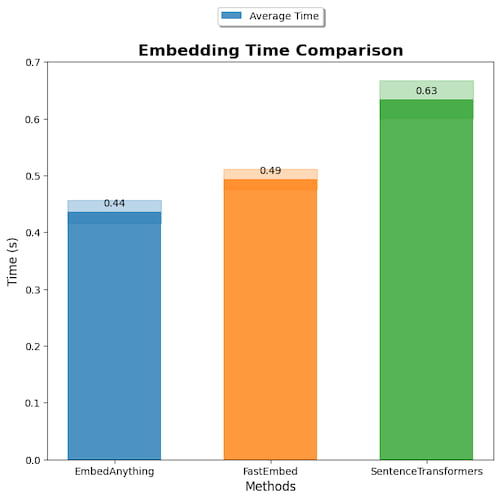
Benchmarks
Only measures embedding model inference speed, on onnx-runtime. Code
⭐ Supported Models
We support any hugging-face models on Candle. And We also support ONNX runtime for BERT and ColPali.
How to add custom model on candle: from_pretrained_hf
model = EmbeddingModel.from_pretrained_hf(
WhichModel.Bert, model_id="model link from huggingface"
)
config = TextEmbedConfig(chunk_size=1000, batch_size=32)
data = embed_anything.embed_file("file_address", embedder=model, config=config)
| Model | HF link |
|---|---|
| Jina | Jina Models |
| Bert | All Bert based models |
| CLIP | openai/clip-* |
| Whisper | OpenAI Whisper models |
| ColPali | starlight-ai/colpali-v1.2-merged-onnx |
| Colbert | answerdotai/answerai-colbert-small-v1, jinaai/jina-colbert-v2 and more |
| Splade | Splade Models and other Splade like models |
| Reranker | Jina Reranker Models, Xenova/bge-reranker |
Splade Models:
model = EmbeddingModel.from_pretrained_hf(
WhichModel.SparseBert, "prithivida/Splade_PP_en_v1"
)
ONNX-Runtime: from_pretrained_onnx
BERT
model = EmbeddingModel.from_pretrained_onnx(
WhichModel.Bert, model_id="onnx_model_link"
)
ColPali
model: ColpaliModel = ColpaliModel.from_pretrained_onnx("starlight-ai/colpali-v1.2-merged-onnx", None)
Colbert
sentences = [
"The quick brown fox jumps over the lazy dog",
"The cat is sleeping on the mat", "The dog is barking at the moon",
"I love pizza",
"The dog is sitting in the park"]
model = ColbertModel.from_pretrained_onnx("jinaai/jina-colbert-v2", path_in_repo="onnx/model.onnx")
embeddings = model.embed(sentences, batch_size=2)
ModernBERT
model = EmbeddingModel.from_pretrained_onnx(
WhichModel.Bert, ONNXModel.ModernBERTBase, dtype = Dtype.Q4F16
)
ReRankers
reranker = Reranker.from_pretrained("jinaai/jina-reranker-v1-turbo-en", dtype=Dtype.F16)
results: list[RerankerResult] = reranker.rerank(["What is the capital of France?"], ["France is a country in Europe.", "Paris is the capital of France."], 2)
For Semantic Chunking
model = EmbeddingModel.from_pretrained_hf(
WhichModel.Bert, model_id="sentence-transformers/all-MiniLM-L12-v2"
)
# with semantic encoder
semantic_encoder = EmbeddingModel.from_pretrained_hf(WhichModel.Jina, model_id = "jinaai/jina-embeddings-v2-small-en")
config = TextEmbedConfig(chunk_size=1000, batch_size=32, splitting_strategy = "semantic", semantic_encoder=semantic_encoder)
🧑🚀 Getting Started
💚 Installation
pip install embed-anything
For GPUs and using special models like ColPali
pip install embed-anything-gpu
Usage
➡️ Usage For 0.3 and later version
To use local embedding: we support Bert and Jina
model = EmbeddingModel.from_pretrained_local(
WhichModel.Bert, model_id="Hugging_face_link"
)
data = embed_anything.embed_file("test_files/test.pdf", embedder=model)
For multimodal embedding: we support CLIP
Requirements Directory with pictures you want to search for example we have test_files with images of cat, dogs etc
import embed_anything
from embed_anything import EmbedData
model = embed_anything.EmbeddingModel.from_pretrained_local(
embed_anything.WhichModel.Clip,
model_id="openai/clip-vit-base-patch16",
# revision="refs/pr/15",
)
data: list[EmbedData] = embed_anything.embed_directory("test_files", embedder=model)
embeddings = np.array([data.embedding for data in data])
query = ["Photo of a monkey?"]
query_embedding = np.array(
embed_anything.embed_query(query, embedder=model)[0].embedding
)
similarities = np.dot(embeddings, query_embedding)
max_index = np.argmax(similarities)
Image.open(data[max_index].text).show()
Audio Embedding using Whisper
requirements: Audio .wav files.
import embed_anything
from embed_anything import (
AudioDecoderModel,
EmbeddingModel,
embed_audio_file,
TextEmbedConfig,
)
# choose any whisper or distilwhisper model from https://huggingface.co/distil-whisper or https://huggingface.co/collections/openai/whisper-release-6501bba2cf999715fd953013
audio_decoder = AudioDecoderModel.from_pretrained_hf(
"openai/whisper-tiny.en", revision="main", model_type="tiny-en", quantized=False
)
embedder = EmbeddingModel.from_pretrained_hf(
embed_anything.WhichModel.Bert,
model_id="sentence-transformers/all-MiniLM-L6-v2",
revision="main",
)
config = TextEmbedConfig(chunk_size=1000, batch_size=32)
data = embed_anything.embed_audio_file(
"test_files/audio/samples_hp0.wav",
audio_decoder=audio_decoder,
embedder=embedder,
text_embed_config=config,
)
print(data[0].metadata)
Using ONNX Models
To use ONNX models, you can either use the ONNXModel enum or the model_id from the Hugging Face model.
model = EmbeddingModel.from_pretrained_onnx(
WhichModel.Bert, model_name = ONNXModel.AllMiniLML6V2Q
)
For some models, you can also specify the dtype to use for the model.
model = EmbeddingModel.from_pretrained_onnx(
WhichModel.Bert, ONNXModel.ModernBERTBase, dtype = Dtype.Q4F16
)
Using the above method is best to ensure that the model works correctly as these models are tested. But if you want to use other models, like finetuned models, you can use the hf_model_id and path_in_repo to load the model like below.
model = EmbeddingModel.from_pretrained_onnx(
WhichModel.Jina, hf_model_id = "jinaai/jina-embeddings-v2-small-en", path_in_repo="model.onnx"
)
To see all the ONNX models supported with model_name, see here
⁉️FAQ
Do I need to know rust to use or contribute to embedanything?
The answer is No. EmbedAnything provides you pyo3 bindings, so you can run any function in python without any issues. To contibute you should check out our guidelines and python folder example of adapters.
How is it different from fastembed?
We provide both backends, candle and onnx. On top of it we also give an end-to-end pipeline, that is you can ingest different data-types and index to any vector database, and inference any model. Fastembed is just an onnx-wrapper.
We've received quite a few questions about why we're using Candle.
One of the main reasons is that Candle doesn't require any specific ONNX format models, which means it can work seamlessly with any Hugging Face model. This flexibility has been a key factor for us. However, we also recognize that we’ve been compromising a bit on speed in favor of that flexibility.
🚧 Contributing to EmbedAnything
First of all, thank you for taking the time to contribute to this project. We truly appreciate your contributions, whether it's bug reports, feature suggestions, or pull requests. Your time and effort are highly valued in this project. 🚀
This document provides guidelines and best practices to help you to contribute effectively. These are meant to serve as guidelines, not strict rules. We encourage you to use your best judgment and feel comfortable proposing changes to this document through a pull request.
🏎️ RoadMap
Accomplishments
One of the aims of EmbedAnything is to allow AI engineers to easily use state of the art embedding models on typical files and documents. A lot has already been accomplished here and these are the formats that we support right now and a few more have to be done.
Adding Fine-tuning
One of the major goals of this year is to add finetuning these models on your data. Like a simple sentence transformer does.
🖼️ Modalities and Source
We’re excited to share that we've expanded our platform to support multiple modalities, including:
-
Audio files
-
Markdowns
-
Websites
-
Images
-
Videos
-
Graph
This gives you the flexibility to work with various data types all in one place! 🌐
💜 Product
We’ve rolled out some major updates in version 0.3 to improve both functionality and performance. Here’s what’s new:
-
Semantic Chunking: Optimized chunking strategy for better Retrieval-Augmented Generation (RAG) workflows.
-
Streaming for Efficient Indexing: We’ve introduced streaming for memory-efficient indexing in vector databases. Want to know more? Check out our article on this feature here: https://www.analyticsvidhya.com/blog/2024/09/vector-streaming/
-
Zero-Shot Applications: Explore our zero-shot application demos to see the power of these updates in action.
-
Intuitive Functions: Version 0.3 includes a complete refactor for more intuitive functions, making the platform easier to use.
-
Chunkwise Streaming: Instead of file-by-file streaming, we now support chunkwise streaming, allowing for more flexible and efficient data processing.
Check out the latest release : and see how these features can supercharge your GenerativeAI pipeline! ✨
🚀Coming Soon
⚙️ Performance
We now support ONNX as well
➡️ Support for GGUF models
- Significantly faster performance
- Stay tuned for these exciting updates! 🚀
🫐Embeddings:
We had multimodality from day one for our infrastructure. We have already included it for websites, images and audios but we want to expand it further to.
☑️Graph embedding -- build deepwalks embeddings depth first and word to vec
☑️Video Embedding
☑️ Yolo Clip
🌊Expansion to other Vector Adapters
We currently support a wide range of vector databases for streaming embeddings, including:
- Elastic: thanks to amazing and active Elastic team for the contribution
- Weaviate
- Pinecone
How to add an adpters: https://starlight-search.com/blog/2024/02/25/adapter-development-guide.md
But we're not stopping there! We're actively working to expand this list.
Want to Contribute? If you’d like to add support for your favorite vector database, we’d love to have your help! Check out our contribution.md for guidelines, or feel free to reach out directly starlight-search@proton.me. Let's build something amazing together! 💡
A big Thank you to all our StarGazers
Star History

Dependencies
~150MB
~2.5M SLoC