1 unstable release
| 0.0.7 | Jun 12, 2024 |
|---|
#418 in Caching
33KB
642 lines
Edge Python API
API to connect to dRISK Edge.
Useful Edge Links
Some useful links for new edge users:
- Log in to edge: demo.drisk.ai
- Documentation: demo.drisk.ai/docs
Installation
pip install drisk_api
Baisc Usage
The API supports the basic building blocs for Create/Read/Update/Delete operations on the graph. For example:
from drisk_api import GraphClient
token = "<edge_auth_token>"
# create or conntect to a graph
new_graph = GraphClient.create_graph("a graph", token)
graph = GraphClient("graph_id", token)
# make a new node
node_id = graph.create_node(label="a node")
# get a node
node = graph.get_node(node_id)
# get the successors of the node
successors = graph.get_successors(node_id)
# update the node
graph.update_node(node_id, label="new label", size=3)
# add edges in batch
with graph.batch():
graph.add_edge(node, other, weight=5.)
More Examples
We can use these building blocks to create whatever graphs we are most interested in. Below are some examples:
Wikepedia Crawler
In this example we will scrape the main url links for a given wikipedia page and create a graph out of it.
Most of the code will be leveraging the wikipedia api and is not particularly important.
What is more interesting is how we can use the api to convert the corresponding information into a graph to then explore it in edge.
First load the relevant module
import wikipedia
from wikipedia import PageError, DisambiguationError, search, WikipediaPage
from tqdm import tqdm
from drisk_api import GraphClient
Let's define some helper functions that will help us create a graph of wikipedia urls for a given page.
The main function to pay attention to is wiki_scraper which will find the 'most important' links in a
given page and add them to the graph, linking back to the original page.
It will do this recursively for each node until a terminal condition is reached (e.g. a max recursion depth).
def find_page(title):
"""Find the wikipedia page."""
results, suggestion = search(title, results=1, suggestion=True)
try:
title = results[0] or suggestion
page = WikipediaPage(title, redirect=True, preload=False)
except IndexError:
raise PageError(title)
return page
def top_links(links, text, top_n):
"""Find most important links in a wikipedia page."""
link_occurrences = {}
for link in links:
link_occurrences[link] = text.lower().count(link.lower())
sorted_links = sorted(link_occurrences.items(), key=lambda x: x[1], reverse=True)
top_n_relevant_links = [link for link, count in sorted_links[:top_n]]
return top_n_relevant_links
def wiki_scraper(
graph,
page_node,
page_name,
string_cache,
visited_pages,
max_depth=3,
current_depth=0,
max_links=10,
first_depth_max_links=100,
):
try:
page = find_page(title=page_name)
except (DisambiguationError, PageError) as e:
return
# add the url to the page_node (and make sure label is right)
graph.update_node(page_node, label=page_name, url=page.url)
if page_name in visited_pages or current_depth >= max_depth:
return
links = top_links(page.links, page.content, first_depth_max_links if current_depth == 0 else max_links)
if current_depth == 0:
tqdm_bar = tqdm(total=len(links), desc="wiki scraping")
for link in links:
if current_depth == 0:
tqdm_bar.update(1)
# see if we have already visted the page
new_page_node = None
if link in string_cache:
new_page_node = string_cache[link]
else:
# if we haven't add a new node and add to cache
new_page_node = graph.create_node(label=link)
string_cache[link] = new_page_node
# link this original page to the new one
graph.create_edge(page_node, new_page_node, 1.)
# repeat for new link
wiki_scraper(
graph,
new_page_node,
link,
string_cache,
visted_pages,
current_depth=current_depth + 1,
max_links=max_links,
first_depth_max_links=first_depth_max_links,
)
visited_pages.add(page_name)
Then we can connect to our graph (or make one):
TOKEN = "<edge_auth_token>"
graph_id = "graph_id"
home_view = "view_id"
g = GraphClient(graph_id, TOKEN)
and run the scraper:
page_name = "Napoleon"
string_cache = {}
visted_pages = set()
page_node = g.create_node(label=page_name)
g.add_nodes_to_view(home_view, [page_node], [(0., 0.)])
with g.batch():
wiki_scraper(
g,
page_node,
page_name,
string_cache,
visted_pages,
max_depth=3,
current_depth=0,
max_links=3,
first_depth_max_links=2,
)
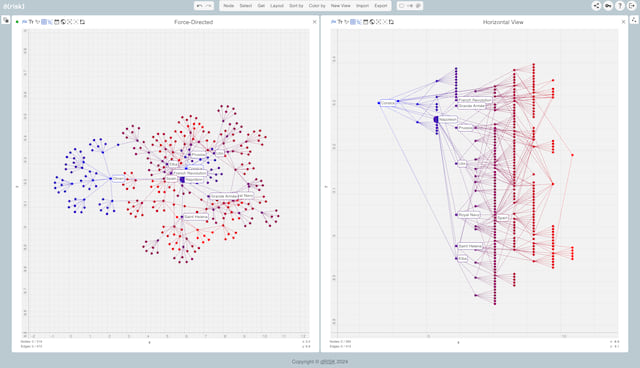
We can then head to edge to interact with the graph:
)))
Dependencies
~3–10MB
~90K SLoC