2 unstable releases
| 0.12.0 | Mar 9, 2025 |
|---|---|
| 0.1.0 | Mar 1, 2025 |
#6 in #vigenere
69 downloads per month
405KB
7.5K
SLoC
➡️
Discord |
Documentation
⬅️
Project ciphey

ciphey is the next generation of decoding tools, built by the same people that brought you Ciphey.
We fully intend to replace Ciphey with ciphey.
✨ You can read more about ciphey here https://skerritt.blog/introducing-ciphey/ ✨
How to Use
The simplest way to use ciphey is to join the Discord Server, head to the #bots channel and use ciphey with $ciphey. Type $help for helpful information!
The second best way is to use cargo install ciphey and call it with ciphey.
You can also git clone this repo and run docker build . it to get an image.
Features
Some features that may interest you, and that we're proud of.
Fast

ciphey is fast. Very fast. Other decoders such as Ciphey require advance artifical intelligence to determine which path it should take to decode (whether to try Caesar next or Base64 etc).
ciphey is so fast we don't need to worry about this currently. For every 1 decode Ciphey can do, ciphey can do ~7. That's a 700% increase in speed.
Library First
There are 2 main parts to ciphey, the library and the CLI. The CLI simply uses the library which means you can build on-top of ciphey. Some features we've built are:
- A Discord Bot
- Better testing of the whole program 💖
- This CLI
Decoders
ciphey currently supports 16 decoders and it is growing fast. Ciphey supports around ~50, and we are adding more everyday.
Timer
One of the big issues with Ciphey is that it could run forever. If it couldn't decode your text, you'd never know!
ciphey has a timer (built into the library and the CLI) which means it will eventually expire. The CLI defaults to 5 seconds, the Discord Bot defaults to 10 (to account for network messages being sent across).
Better Docs, Better Tests
ciphey already has ~120 tests, documentation tests (to ensure our docs are kept up to date) and we enforce documentation on all of our major components. This is beautiful.
LemmeKnow

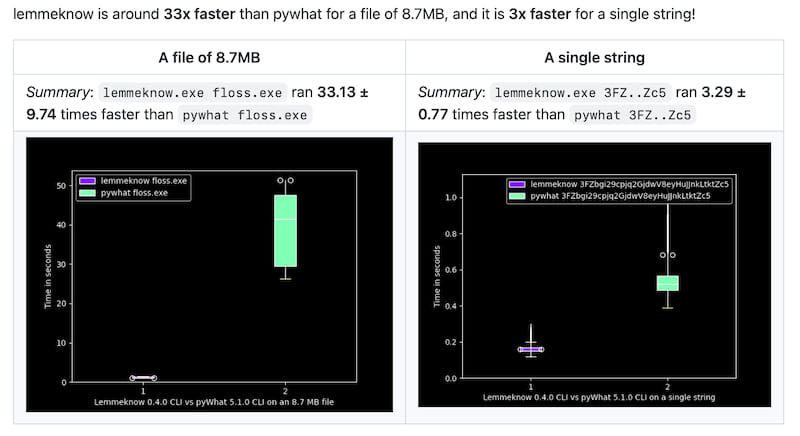
LemmeKnow is the Rust version of PyWhat. It's 33 times faster which means we can now decode and determine whether something is an IP address or whatnot 3300% faster than in Python.
Multithreading
Ciphey did not support multi-threading, it was quite slow. ciphey supports it natively using Rayon, one of the fastest multi-threading libraries out there.
While we do not entirely see the effects of it with only 16 decoders (and them being quite fast), as we add more decoders (and slower ones) we'll see it won't affect the overall programs speed as much.
Multi level decodings
Ciphey did not support multi-level decryptions like a path of Rot13 -> Base64 -> Rot13 because it was so slow. ciphey is fast enough to support this, although we plan to turn it off eventually.
Configurable Sensitivity for Plaintext Detection
ciphey now supports configurable sensitivity levels for gibberish detection, allowing for more accurate plaintext identification across different types of encodings. Classical ciphers like Caesar use Low sensitivity to better handle English-like results, while most other decoders use Medium sensitivity by default.
This feature helps reduce false positives and negatives in plaintext detection, making ciphey more reliable across a wider range of encoded texts.
Enhanced Plaintext Detection with BERT
ciphey now offers enhanced plaintext detection using a BERT-based model from the gibberish-or-not crate. This feature:
- Increases plaintext detection accuracy by approximately 40%
- Reduces false positives and negatives when identifying plaintext
- Can be enabled during first-run setup or later with
ciphey --enable-enhanced-detection - Requires a one-time download of a 500MB AI model (requires a free Hugging Face account)
New Features
Better search algorithm
We now use A* search. This is very fast.
A* works by using a heuristic to estimate the cost of reaching the goal from the current state.
First, we ignore the heuristic for very fast decoders like Base64 and ensure we run them first each time on each node.
Then, we calculate the heuristic for the remaining decoders using cipher_identifier which can determine the probability a given string is a certain cipher.
We store previous results in a cache to avoid recalculating the same path.
We prune the search tree to avoid unnecessary calculations and keep the memory usage down if it gets too bad.
We also keep track of statistics on decoders to dynamically prioritise decoders that work better (example: caesar is popular, but Beaufort is not so Caesar will dynamically be prioritised over Beaufort)
Finally, we keep track of popular pairs. So base64 -> base64 is very popular, so we prioritise that path (among others).
Custom themes
You can now set a custom theme for ciphey. This is useful if you want to make ciphey look different.
This also helps with accessibility.
Vigenere
We now use perhaps the best algorithm for Vigenere.
It's fast, accurate and handles non-letter characters better than any other algorithm.
Better English checking
We use a qudgaram / trigram / english dict checker to calculate probability of plaintext.
We change the thresholds depending on the cipher. Example is that Caesar returns text that "looks" like english, whereas base64 does not.
As well as this, we have a database of popular regex (about 500) of api keys, mac addresses, etc.
We also have a is_password function to determine if a string is an exact password seen in a data dump.
More ciphers
- Braille
- Atbash
- Vigenere
Database
We now store statistics in a database. This is useful for seeing how ciphey is doing over time.
Dependencies
~44–59MB
~1M SLoC