15 releases (5 breaking)
| 0.6.5 | Aug 10, 2024 |
|---|---|
| 0.6.4 | Jul 24, 2024 |
| 0.6.3 | Jan 17, 2024 |
| 0.5.1 | Dec 14, 2023 |
| 0.1.1 | Dec 12, 2023 |
#165 in Concurrency
1,206 downloads per month
100KB
751 lines
Batch ain't one
I got 99 problems, but a batch ain't one...
Batch up multiple items for processing as a single unit.
Why
Sometimes it is more efficient to process many items at once rather than one at a time. Especially when the processing step has overheads which can be shared between many items.
Example: Inserting multiple rows into a database
For example, each database operation – such as an INSERT – has the overhead of a round trip to the database.
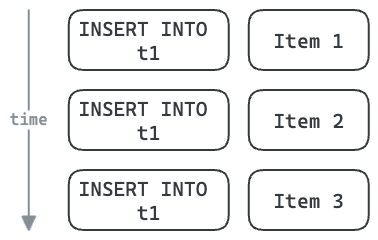
Multi-row inserts can share this overhead between many items. This also allows us to share a single database connection to insert these three items, potentially reducing contention if the connection pool is highly utilised.

Example: With transactions and locking
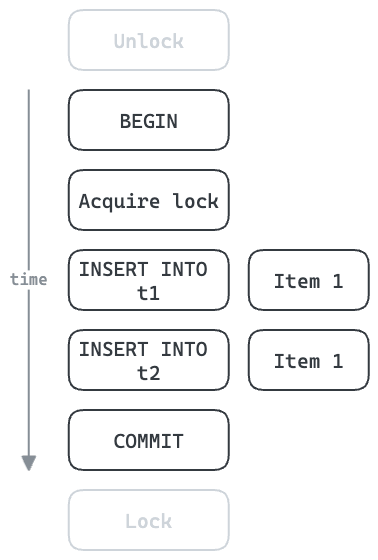
Inserts into database tables can often be done concurrently. In some cases these must be done serially, enforced using locks. This can be a significant throughput bottleneck.
In the example below, five round trips to the database are necessary for each item. All subsequent items must wait until this is finished. If each round trip takes 1ms, then this results in a minimum of 5ms per item, or 200 items/sec maximum.
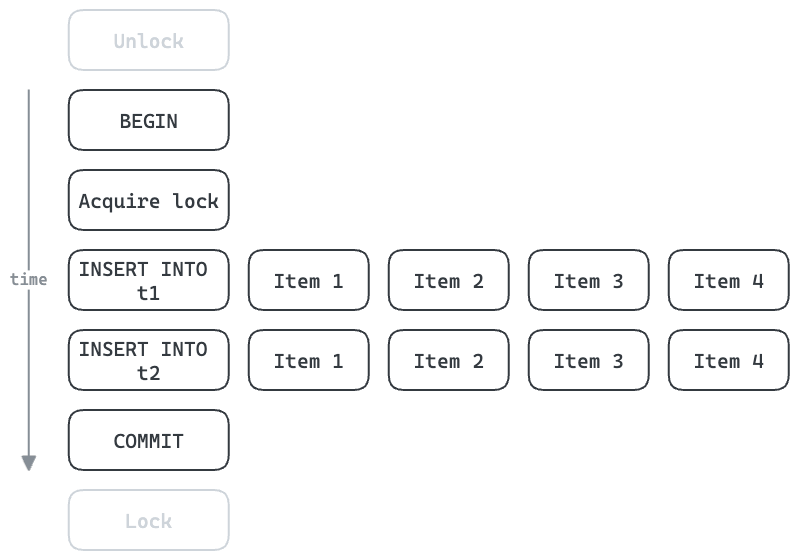
With batching, we can improve the throughput. Acquiring/releasing the lock and beginning/committing the transaction can be shared for the whole batch. With four items per batch, we can increase the theoretical maximum throughput to 800 items/sec. In reality, the more rows each INSERT processes the longer it will take, but multi-row inserts can be very efficient.
How
A worker task is run in the background and items are submitted to it for batching. Batches are processed in their own tasks, concurrently.
Example
use std::{time::Duration, marker::Send, sync::Arc};
use async_trait::async_trait;
use batch_aint_one::{Batcher, BatchingPolicy, Limits, Processor};
/// A simple processor which just sleeps then returns a mapped version
/// of the inputs.
#[derive(Debug, Clone)]
struct SleepyBatchProcessor;
#[async_trait]
impl Processor<String, String, String> for SleepyBatchProcessor {
async fn process(
&self,
key: String,
inputs: impl Iterator<Item = String> + Send,
) -> Result<Vec<String>, String> {
tokio::time::sleep(Duration::from_millis(10)).await;
// In this example:
// - `key`: "Key A"
// - `inputs`: ["Item 1", "Item 2"]
Ok(inputs.map(|s| s + " processed for " + &key).collect())
}
}
tokio_test::block_on(async {
// Create a new batcher.
// Put it in an Arc so we can share it between handlers.
let batcher = Arc::new(Batcher::new(
// This will process items in a background worker task.
SleepyBatchProcessor,
// Set some limits.
Limits::default()
.max_batch_size(2)
.max_key_concurrency(1),
// Process a batch when it reaches the max_batch_size.
BatchingPolicy::Size,
));
// Request handler 1
let batcher1 = batcher.clone();
tokio::spawn(async move {
// Add an item to be processed and wait for the result.
let output = batcher1.add("Key A".to_string(), "Item 1".to_string()).await.unwrap();
assert_eq!("Item 1 processed for Key A".to_string(), output);
});
// Request handler 2
let batcher2 = batcher.clone();
tokio::spawn(async move {
// Add an item to be processed and wait for the result.
let output = batcher2.add("Key A".to_string(), "Item 2".to_string()).await.unwrap();
assert_eq!("Item 2 processed for Key A".to_string(), output);
});
});
Roadmap
- Tests
- Better error handling
- Docs
- Why – motivating example
- Code examples
- Tracing/logging
- Metrics?
Further reading
Dependencies
~2.5–8.5MB
~67K SLoC